

.png)
In today’s world, every system generates a huge volume of data daily and companies want to use this data to gain a competitive edge. You can say data is the new oil. But to process this data, companies need to give it a form and structure by assembling it in an organized and unified place through a streamlined data integration process, preferably in data warehouses, data lakes, or any data management platform.
And that’s where ETL tools step in.
These tools help structure raw data and thus play a significant role in SAS data management and help businesses take data analytics to the next level.
Several types of ETL tools in the market automate building, managing, and monitoring a data pipeline. In this article, we touch upon the ETL process and explore some enterprise ETL tools in the market.
What is ETL?
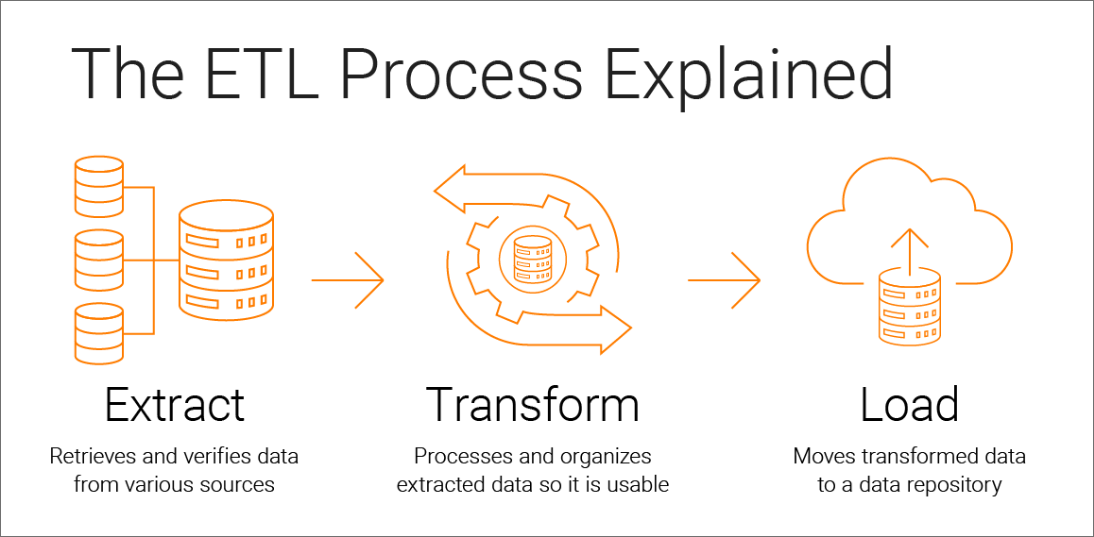
ETL stands for “Extract, Transform and Load”. ETL is a process of extracting data from different data sources, cleansing and organizing it, and eventually, loading it to a target data warehouse or a Unified data repository.

Why ETL?
In today's data-centric world, ETL plays a vital role in maintaining the integrity of a company by keeping its data up to date. To get the correct insight it is therefore important to perform ETL mainly due to the following reasons:
1. Data Volumes: The generated data has very high volume and velocity as many organizations have historical as well as real-time data flows being forged continuously from different sources.
2. Data Quality: The quality of the generated data is not exemplary as data is present in different formats like online feeds, online transactions, tables, images, excel, CSV, JSON, text files, etc. Data can be structured or unstructured, so to bring all different data formats to one homogeneous format performing the ETL process is highly needed.
To overcome these challenges many ETL tools are developed that make this process easy and efficient and help organizations combine their data by going through processes like de-duplicating, sorting, filtering, merging, reformatting, and transforming to make data ready for analysis.
ETL in detail:
1. Extract:
Extraction is the first step of the ETL process that involves data being pulled from different data sources. It can extract data from the following sources listed below
- Data Storage Platform & Data warehouses
- Analytics tool
- On-premise environment, hybrid, and cloud
- CRM and ERP systems
- Flat files, Email, and Web Pages
Manual data extraction can be highly time-consuming and error-prone, so to overcome these challenges automation of the Extraction process is the optimal solution. Data Extraction: Different ways of extracting data.
Data Extraction: Different ways of extracting data.
1.1. Notification-based
In Notification-based extraction whenever data is updated, a notification is generated either through data replication or through webhooks (SaaS application). As soon as the notification is spawned data is pulled from the source. It is one of the easiest ways to detect any update but is not doable for some data sources that may not support generating a notification.
1.2. Incremental Extraction
In incremental extraction, only records that have been altered or updated are extracted/ingested. This extraction is majorly preferred for daily data ingestion as low-volume data is transferred making the daily data extraction process efficient. One major drawback of this extraction technique is once the extracted data is deleted it may not be detected.
1.3. Complete data extraction
In complete data extraction, the entire data is loaded. If a user wants to get full data or to ingest data for the first time then complete data extraction is preferred. The problem with this type of extraction is that if the data volume is massive it can be highly time-consuming.
Challenges in Data Extraction:
Data extraction is the first and foremost step in the ETL process, so we need to ensure the correctness of the extraction process before proceeding to the next step. Data can be extracted using SQL or through API for SaaS, but this way may not be reliable as the API may change often or be poorly documented and different data sources can have various APIs.
This is one of the major challenges faced during the data extraction process, other challenges are mentioned below.
- Changing data formats
- Increasing data volumes
- Updates in source credentials.
- Data issue with Null values
- Change requests for new columns, dimensions, derivatives, and features.
2. TRANSFORM
Transform is the second step of the ETL process, in this raw data undergoes processing and modifications in the staging area. In this process, data is shaped according to the business use case and the various business intelligence requirements.
The transformation layer consists of some of the following steps:
- Removing duplicates, cleaning, filtering, sorting, validating, and affirming data.
- Data inconsistencies and missing values are determined and terminated.
- Data encryption or data protection as per industrial and government rules is implemented for security.
- Formatting regulations are applied to match the schema of the target data repository
- Unused data and anomalies are removed
Data Transformation: Different ways of transforming data
2.1. Multistage Data Transformation –
In multistage data transformation, data is moved to an intermediate area or staging area where all the transformation steps take place then eventually data is transferred to the final data warehouse where the business use cases are implemented for better decision-making.
2.2. In-Warehouse Data Transformation –
In ‘In-Warehouse Data Transformation', data is first loaded into the data warehouse, and then all the subsequent data transformation steps are performed aws data pipeline. This approach of transforming data is followed in the ELT process.
Challenges in Data Transformation
Data transformation is the most vital phase of the ETL process as it enhances data quality and guarantees data integrity yet there are some challenges faced when transforming data comes into play. Some challenges faced in transforming data are mentioned below:
- Increasing data volumes makes it difficult to manage data and any transformation made can result in some data loss if not done properly.
- The data transformation process is quite time-consuming and the chances of errors are also very high due to the manual effort.
- More manpower and skills are required to efficiently perform the data transformation process which may even lead businesses to spend high.
3. LOAD
Once data is transformed, it is moved from the staging area to the target database or data warehouse which could be on the cloud or on-premise. Initially, the entire data is loaded, and then recurring loading of incremental data occurs. Sometimes, a full fetch of data takes place in the data warehouse to erase and replace old data with new ones to overcome data inconsistencies.
Once data is loaded, it is optimized and aggregated to improve performance. The end goal is to quicken up the query span for the analytics team to perform accurate analysis in no time.
Data Loading: Considerations for error-free loading
- Referential integrity constraint needs to be addressed effectively when new rows are inserted or a foreign key column is updated.
- Partitions should be handled effectively to save costs on data querying.
- Indexes should be cleared before loading data into the target and rebuilt after data is loaded.
- In Incremental loading, data should be in synchronization with the source system to avoid data ingestion failures.
- Monitoring should be in place while loading the data so that any data loss creates warning alerts or notifications.
Challenges in Data Loading:
Data loading is the final step of the ETL process. This phase of ETL is responsible for the execution of correct data analysis. Therefore one must ensure that the load data quality is up to the mark. The main challenge faced during data loading is mentioned below:
- Data loss – While loading the data into the target system, there might be API unavailability, network congestion/failure or API credentials may expire these factors can result in complete data loss posing a greater threat to the business.
Overall Challenges of ETL
1. Code Issues
If ETL pipeline code is not optimized or manually coded, then such inefficiencies might affect the ETL process at any stage: It may cause problems while extracting data from the source, transforming data, or loading data into the target data warehouse and backtracking the issue can even be a tedious task.
2. Network Issues
The ETL process involves massive data transfer and processing daily which needs to be quick and efficient. So, the network needs to be fast and reliable, high latency of the network may create unexpected troubles in any of the stages and any network outage may even lead to data loss.
3. Lack of resources
Lack of any computing resources including storage, slow downloading, or lagging data processing in ETL may lead to fragmentation of your file system or create caches over some time.
4. Data Integrity
Since ETL involves collecting data from more than one source, if not done rightly, data might get corrupted which may create several inconsistencies and hence can cause data health reduction. So latest data needs to be carefully collected from sources and transformation techniques should be used accordingly.
5. Maintenance
In any organization increase in data corresponds to an increase in data sources so for business to maintain all their enormous data in a unified place more data connectors will keep on adding. So, while planning the ETL process, scalability, maintenance, and the cost of maintenance should always be considered.
ETL vs ELT?
The main difference between ETL and ELT is the order of transformation, in ETL it happens before loading the data into the cloud data warehouses' warehouse however in ELT, data is first loaded and then its transformation takes place in the cloud data warehouse itself.
ELT Benefits over ETL
- When dealing with high volumes of data ELT has a better advantage over ETL as transforming data before loading it into the data warehouse is an error-prone process and any mistake during transformation can cause complete data loss. Whereas in ELT data is first loaded into the warehouse and then it is transformed. So the chances of data loss are minimized in ELT as the data sits in the warehouse itself.
- In ELT, not much planning is required by the team as compared to the ETL process. In ETL proper transformation rules need to be identified before the data loading process is executed which can be very time-consuming.
- ELT is ideal for big data management systems and is adopted by organizations making use of cloud technologies, which is considered an ideal option for efficient querying.
- For ETL, the process of data ingestion is very slow and inefficient, as the first data transformation takes place on a separate server, and after that data loading process starts. ELT does much faster data ingestion, as there is no data transfer to a secondary server for any restructuring. In fact, with ELT data can be loaded and transformed simultaneously.
ELT as compared to ETL is much faster, scalable, flexible, and efficient for large datasets which consist of both structured and unstructured data. ELT also helps to save data egress costs as before the transformation process the data sits in the data warehouse only.
Some of the popular 21 ETL tools in the space are mentioned below along with their Pros and Cons to help you choose the right ETL tool according to your needs.
1. Sprinkle Data
Sprinkle is a cloud-based ELT tool with No-Code data integration and transformation capabilities proven to give accurate analysis with an easy-to-use user interface. It brings data from different sources to the target destination in real-time, without writing even a single line of code hence helping to save on cost.
It supports integration with more than 100+ data sources, including databases, cloud storage, files, and events. Along with that, it has the most widely used databases and applications across the industry.
The core technology of Sprinkle is a semantic layer that includes Ingestion, transformation, exploration, and catalog features, it runs on top of your infrastructure. This allows data teams to collaborate and do data integration workflows across the entire lifecycle of data without writing any code.

Pros of Sprinkle Data:
- Zero-code Ingestion: Automatic schema discovery and mapping of data types to the warehouse types are supported in Sprinkle enabling users to ingest their data without any hassles. It supports all types of data, including JSON type.
- Data Exploration: It facilitates visualization of data during data exploration for better understanding. It has built-in visualization so that data teams can explore and collaborate on data with ease
- No proprietary Transformation code: Sprinkle does ELT, which offers much more flexibility and scaling than the ETL. Its extended data transformation capabilities using SQL or Python make it much more flexible for all users.
- Jupyter Notebook: It also has Python notebook support to perform exploratory data analysis and can also be used to work with machine learning algorithms.
- Storage on the customer side(On-Premise): Sprinkle offers an Enterprise version that can run on the customer's VM, within the Cloud, or on-premise, so data does not go outside the customer network, which keeps data safe and secure.
- Cost Effective: Sprinkle's pricing plans provide unlimited rows, so users need not worry about rising costs as their business and data grow. Sprinkle pricing plans are highly scalable.
- Monitoring: With high-intelligence alerts and activity logs, the health of any pipeline can be monitored easily, and any issue in the pipeline can be resolved quickly.
- Customer Support: Sprinkle customer support is very efficient and fast. From the day of trial, sprinkle support is available with live chat, email, and on-call support, providing great assistance.
- Professional Services: Sprinkle provides professional services to its customers who don't have any in-house resources.
Cons of Sprinkle Data:
- Some of the chart types are not supported yet.
- Dashboards and reports in Sprinkle can be made more interactive.
2. Stitch data
Stitch is a cloud open-source platform that consolidates data from different sources to help you analyze and govern data effortlessly. It is a simple, extensible ETL tool built for data teams and offers a robust transformation framework to foster data analysis in no time.

Pros of Stitch Data:
- It can be smoothly integrated with Singer, an open-source tool from Stitch.
- It offers a volume-based pricing model that permits users to pick plans according to their usage and requirements. ETL using stitch is highly scalable, which makes it one of the most preferred ETL tools in the market
- It supports a large number of data sources that are either built in-house or community-supported.
- It provides transparency and complete control to manage your data pipeline effectively.
- Stitch Supports compliance standards such as SOC 2, HIPAA, and GDPR.
- This ETL tool also provides Column-oriented databases, massively parallel processing (MPP), end-to-end data encryption, network isolation, fault tolerance, and concurrency limits.
- It provides customer support via call and chat.
- It supports cloud, Windows, and Web-Based platforms
- It has a 14-day free trial period for users to get a basic understanding of the product.
Cons of Stitch Data:
- It offers only a SaaS deployment model that cannot be hosted on your servers.
- It cannot perform transformations using Python script.
- It cannot explore data quickly. NoSQL support
- In Stitch, users must rely on additional tools to debug or build quick reports.
- It doesn't build new APIs for customers on request.
- For data replication, a round-trip from your data source servers to your data warehouse via the Stitch servers leads to high data egress costs charged by cloud providers.
- Incremental Transforms with Partition management are not supported
Check the detailed comparison of Stitch vs Sprinkle
3. AWS Glue
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. It is one of the most efficient ETL data warehouses and tools. AWS Glue provides all the capabilities needed for data integration so that users can start with their data analysis journey.

Pros of AWS Glue:
- It easily Integrates with AWS, HTTP, MOCK, and Elastic Load Balancing.
- It provides automatic schema discovery.
- AWSGlue jobs allow you to invoke on a schedule, on-demand, or based on a specific event.
- AWSGlue meets compliance standards such as PCI-DSS, HIPAA/HITECH, FedRAMP, GDPR, FIPS 140-2, and NIST 800-171.
- It supports integration with PostgreSQL, MySQL, MariaDB, Oracle Database, and SQL Server.
- It supports multiple output formats such as JSON, CSV, Parquet, ORC, Avro, and Grok.
- It provides data privacy and makes data customization easy.
- It provides customer support via the Contact Form.
- It Supports Cloud, SaaS, and Web-Based platforms as well.
- A free trial period of 30 days is provided to familiarize yourself with the product.
Cons of AWS Glue:
- AWS Glue is not friendly to non-technical users as all the tasks run in Apache Spark so only developers who understand Python or Scala can work on it.
- It doesn't have integration with SaaS applications.
- AWS Glue is limited to only the AWS ecosystem.
- The major drawback is that no real-time support is provided.
- It doesn't provide real-time data for complex operations.
Check the detailed comparison of AWS Glue vs Sprinkle
4. Fivetran
Fivetran is a cloud-based ETL tool known for its many custom data source integrations. Fivetran has resource-driven schemas that are pre-built, automated, and ready to query. In this open-source ETL tool, data source integration is the most distinctive feature that makes it unique from the other open-source ETL tools in the market.

Pros of Fivetran:
- Fivetran provides post-load transformation functionality for modeling from SQL-based transformations.
- Fivetran provides a huge number of data connectors.
- Fast setup and plug-and-play integration with any application are provided.
- Automatic schema migrations, which require zero coding for transformations, are a plus for people who are not well-versed in coding.
- Fivetran pricing plans are highly scalable. Only the active rows are considered when it comes to pricing.
- It supports SQL-based transformation after the data loading is completed.
Cons of Fivetran:
- An external tool for visualization is required as Fivetran is only an ETL tool.
- Fivetran only offers one-direction data sync and doesn't provide two-way directional sync
- The users cannot control the data sent to any specific destination.
- It doesn't provide any on-premise solution.
- Fivetran doesn't support Python for data transformations.
Check the detailed comparison of Fivetran vs Sprinkle
5. Hevo data
Hevo Data is a data management pipeline that transfers data from different data sources to a data warehouse of your choice. It provides a consistent and reliable solution to manage data in real-time. It allows you to focus on key, business intelligence needs and perform insightful analysis using tools like Tableau, Power BI, etc.

Pros of Hevo Data:
- Hevo Data supports integration with a high number of data sources, databases, SDKs, cloud storage, and streaming services, making it one of the most diverse ETL tools available in the sector.
- It provides extracting, transforming, and loading data to and from databases, and more importantly, the speed of these operations is very high.
- Hevo Data can detect the schema of incoming data and replicate the same in the data warehouse.
- Hevo is built on a real-time streaming architecture to load the data to your warehouse in real time.
- It has a fast and simple setup making it easier for first-time users.
- Hevo is GDPR, SOC II, and HIPAA compliant.
- A free trial for 14 days is available.
Cons of Hevo Data:
- It offers only a SaaS deployment model that cannot be hosted on your servers.
- This ETL tool cannot perform transformations in Python, unlike the other ETL tools.
- Cannot explore data quickly.No SQL support.
- For debugging or for building quick reports, one needs to rely on other tools.
- It doesn't build new APIs for customers on request.
- For data replication, a round-trip from your data source servers to your data warehouse via the Hevo servers leads to high data egress costs charged by cloud providers.
Check the detailed comparison of Hevo vs Sprinkle
6. Integrate.io
Integrate.io is a low-code data warehouse data integration platform, specially designed for e-commerce. It has many connectors to create and manage automated pipelines in no time. This ETL tool helps create effortless data transformations, salesforce to salesforce Integration and promotes data security.

Pros of Integrate IO:
- It has quick customer service via live chat, email, and phone. The response time of customer support is also very short.
- Integrate.io platform is very easy to use and flexible, with a user-friendly interface it ensures the best quality platform experience for its users.
- Low code implementation is provided to the users.
- A free trial of 14 days is provided for users to get a hands-on experience with the product.
- Highly scalable and flexible paid plans are provided by integrate.io.
- It is Supported on Cloud, Windows, and Linux and is web-based.
Cons of Integrate IO:
- Difficult to debug errors in complex transformations as compared to other ETL tools.
- Hard to rectify the cause of the error from the error logs.
- drag-and-drop interface becomes tough to use for handling complicated pipelines.
7. CData Sync
CData Sync is one of the most simple-to-use no-code platforms for replication of data pipeline from all Cloud/SaaS data to any database or data warehouse in minutes. It helps in integrating different sources like MySQL, Postgres, and Oracle, similar to the other ETL tools. CData brings in data seamlessly with JDBC and ODBC drivers.

Pros of CData Sync:
- Configuring connection is very easy in CData Sync as compared to other ETL tools.
- Replication of data into any warehouse is very easy.
- In CData Sync, data can be replicated from 150+ enterprise data sources providing flexibility to its users.
- A 30-day free trial period is provided for users to get familiar with the platform.
- CData Sync has very reliable customer support facilitated through chat, phone, and email.
Cons of CData Sync:
- The documentation for CData Sync functionality especially for the advanced features is not available.
- It does not send updates via email or notify users about the jobs. Monitoring of jobs is not proper.
- There is no incremental upload for connectors and incremental update of data is not supported as offered by other ETL tools.
8. Talend
Talend is an open-source ETL tool mainly designed for building data pipelines. It is mainly used to convert, integrate, and update data from various sources. Data from Excel, Dropbox, Oracle, Salesforce, and other data sources can be connected to run jobs through drag and drop GUI of Talend Open Source.

Pros of Talend:
- It is an open-source ETL tool that provides more security and as it is an open-source tool it has fewer bugs and faster fixes as compared with other ETL tools.
- It helps in the creation of complex applications by using an easy drag-and-drop interface.
- Instantly email alerts are shared with the users in Talend whenever a job fails or is not working as expected.
- It is easy to connect Talend to different databases on different platforms.
- To keep an eye on scheduling and monitoring additional advanced features are provided by the platform.
Cons of Talend:
- This platform is sometimes inefficient as some of the running jobs consume more CPU and Memory.
- Some issues are faced when users are working with datasets having large data volumes. If your business produces vast volumes of data daily then other ETL tools should be considered.
- It is less suitable for small-scale deployments in SMB environments.
9. IBM DataStage
IBM DataStage is an ETL tool used for data integration that is built around a client-server design. It supports universal business connectivity and extended metadata management.
This tool is designed to support ETL and ELT models and integrate data across multiple data sources and applications while maintaining high performance.

Pros of IBM DataStage:
- It supports a single interface for the integration of heterogeneous data sources and applications.
- Its easy-to-use interface is really helpful for first-time users as collated with the other ETL tools
- Output formats such as CSV and TXT are supported which provides great flexibility to its users.
- It gives a lifetime free basic plan to users and paid plans are also well-designed by keeping scalability in consideration.
- It has great mapping tools that make it easy to perform data ready for analysis.
- Its well-designed process is proven to be efficient and Parallelism makes loading fast.
- The platform is robust and fast in processing relatively larger datasets with ease.
Cons of IBM DataStage:
- The propagation of metadata along with the data is very complex and can be made simpler like other ETL tools.
- The connectivity with heterogeneous systems is limited so data coming from different sources may be restricted.
- It does not have automated error handling and recovery.
- Integrations between IBM DataStage and other products are limited.
10. Skyvia
Skyvia is a cloud-based platform that offers fully customizable data sync. It supports a wide range of cloud applications, databases, cloud data warehouses, APIs, etc. Skyvia supports ETL, ELT, and reverse ETL functionality. It has flexible billing plans which makes it suitable for enterprise companies and startups to make use of this platform.

Pros of Skyvia:
- Data mobility is made simpler as users can move their data between different cloud apps in just a few clicks.
- It consists of pre-defined templates for data integration scenarios making it distinct from other ETL tools.
- It is a low-code platform for data sources.
- In case of an intricate error, it provides different facilities for failure alerts and also gives detailed error logs.
- It makes complex data transformations easy.
Cons of Skyvia:
- This platform does not provide any live support so it may become tough for users to clear their queries.
- Sometimes the synchronization process in this ETL tool is quite time-consuming as compared to the other ETL tools in the market.
11. Oracle Data Integrator
Oracle Data Integrator (ODI) is mainly designed for building and maintaining data integrations. It is suitable for companies that require minimal migrations. It offers to build integrations and performs more efficiently because of its parallel execution of tasks. It has an easy flow-based and easy-to-understand graphical user interface, making it easy to familiarize yourself with the platform.

Pros of Oracle Data Integrator:
- Documentation is provided by Oracle Data Integrator to use the product. The documentation gives step-by-step procedures making it easy for users to use the platform.
- A large number of transformation options are available which gives users the flexibility to choose the apt transformation technique according to their needs.
- Easy and fast data integration with Oracle is a plus.
- The platform can handle high data volumes every day and ensure its efficient working.
- Big Data extraction is flexible with ODI.
Cons of Oracle Data Integrator:
- The pricing plans are very flexible but still, the cost of the plan is high.
- The automatically generated code is not easy to comprehend. So if you are not into advanced coding other ETL tools should be preferred.
- Although the platform is highly secure but still security setup is hard to maintain and requires more effort.
12. Dataddo
Dataddo is a no-code platform that enables users to integrate data irrespective of their technical skills. It comes up with various features like data pipelines, customizable metrics, and a wide range of connectors. Users can easily create pipelines and API changes are managed by the Dataddo team itself. They keep on adding new connectors as it takes around 10 business days to add a new connector.

Pros of Dataddo:
- The platform has a user-friendly interface with an easy-to-use GUI is a plus for people with less technical acumen.
- Data pipelines can be deployed even after minutes of account creation.
- No maintenance is required and API changes are managed by the Dataddo team itself.
- Data source blending is also available within Dataddo providing flexibility to users.
Cons Dataddo:
- The complexity of the pricing plans is so high that sometimes users face difficulties while canceling their subscriptions.
- It is a tedious task to add custom fields for the final data analysis report which creates hassles in dashboarding.
13. X-tract.io
X-tract.io is a data integration tool that integrates high-quality data with business datasets. These can be imported to the cloud with high efficiency and less time consumption. It has features like monitoring capabilities that help businesses to gain insights and to spot hidden patterns in their data. It has a unique monitoring feature as contrasted with the other ETL data integration tools around, that helps to keep an eye on the market competition as well.

Pros of X-tract.io:
- Xtract.io is an AI-driven ETL platform that makes it more efficient and reliable to use as compared with the other ETL tools, as chances of error are minimized to a greater extent.
- It combines data from different sources, removes duplicates, and allows data to become more consumable, just like other ETL tools.
- It has powerful dashboards and reports that help users for better decision making.
Cons of Xtract.io:
- The absence of documentation is a bigger problem faced by many users, so it may be difficult for new users to get familiar with the platform.
- Xtract.io is not supported on Linux which makes this platform less flexible as compared to other ETL tools.
14. QuerySurge
QuerySurge is an ETL testing tool that enhances data quality and aids in automating manual testing efforts. It is primarily developed by RTTS. It provides numerous benefits like integration with MySQL, Oracle, and PostgreSQL helping users to make the ETL process more convenient and smooth. This tool can quicken up the data quality process for its users.

Pros of QuerySurge:
- Testing is allowed on more than 200 platforms including data warehouses, Hadoop & NoSQL lakes, databases, flat files, XML, JSON, BI reports, mainframe, and others.
- The testing is automated and reduces manual effort thus reducing the chances of human errors as well.
- The software integration is very reliable and secure and is trusted by many users.
- It has a free trial for up to 30 days to get a hands-on experience on the platform for the users.
- The support team closely works with the clients to resolve their queries as fast as possible. The support team is also very responsive.
Cons of QuerySurge:
- For large datasets, the automated pipelines are time-consuming as processing time is very high.
- Top features are only accessible with a premium subscription.
- The pricing plans are flexible but are still very confusing for the users.
- The UI is a little old-fashioned and sometimes users find it difficult to navigate to different pages which is not the case with other ETL tools.
15. Rivery
It is one of the best ETL tools with numerous features such as a no-code platform that uses native Python as its primary language. It provides a fully managed solution for data ingestion and is capable of automating all data processes making it easy for businesses to manage their data effectively. It has connectivity with the cloud and has more than 200 connectors. With top-notch security and customization features, it is one of the most preferred ETL tools.

Pros of Rivery:
- The interface for Rivery is very simplified and user-friendly
- Customer support is very quick and efficient.
- The connectors are robust and the list of connectors is also growing rapidly.
- The transformation layer makes complex workflows organized.
- Data models are already built and ready-made templates are provided facilitating the creation of data pipelines in no time.
Cons of Rivery:
- Roles functionality is not introduced yet unlike other ETL tools. Different roles cannot be defined for different users
- Documentation for some newly introduced features is not available in time.
16. JasperSoft
JasperSoft is an open-source ETL tool launched in 1991 and has headquarters in California, United States. It extracts and transforms data from multiple sources and loads the data in a warehouse for analysis and reporting. It defines complex mappings and transformations with diverse transformation components. It is a well-known ETL tool for its accurate data analysis that helps businesses boost customer satisfaction by rectifying ongoing trends.

Pros of JasperSoft:
- Complex Applications can be created by using an easy drag-and-drop interface.
- It is easy to connect to different databases on different platforms.
- There are advanced features for scheduling and monitoring available.
- The reports are created from scratch and are highly customizable and the sub-report elements allow users to perform in-depth analysis by creating complex reports.
- The software provides a variety of output formats and can create HTML 5 charts as well.
Cons of JasperSoft:
- It doesn't work well with high volumes of data.
- Its performance slows down as the data handling limit is reached. If your organization produces huge amounts of data daily then other ETL tools should be considered.
- Complex dashboard and report creation is slightly tough.
- There are limited chart options for reporting and generating reports with factory tools is also limited
17. Microsoft SQL Server Integration Services (SSIS)
Microsoft SQL server integration service is a product developed for data integration and migration. It makes data integration efficient as the process of the data integration processes and transformation takes place in the memory itself. As it is the product of Microsoft, it only supports MSS.

Pros of Microsoft SQL Server Integration services:
- Data can be moved efficiently from source to destination using its import/export wizard.
- It has a user-friendly drag-and-drop interface and good technical support is also provided.
- All the activities related to data sources are easily captured.
- Using plug-ins, it can be integrated with Salesforce and CRM.
- It has increased data security ensuring the security of the database
- Data can be loaded parallelly to many destinations.
Cons of Microsoft SQL Server Integration services:
- It has a high memory usage.
- It can easily integrate data only from Microsoft SQL Server. Integration of data from JSON and Excel is very tough.
- The errors thrown are unclear a proper error propagation is not there which makes it difficult to debug the error.
- Transforming data is a laborious process in the platform, especially when dealing with flat files.
18. BigEval
BigEval is specially designed to automate the data warehousing and integration process. This automation is capable of eliminating the manual effort of testing the ETL/ELT process and data warehousing. Every test goes through the same process step by step as we do it manually. It also has hundreds of test case templates to ensure good data quality.

Pros of BigEval:
- It supports compliance standards such as GPDR.
- Output formats such as CSV and PDF are supported.
- Instant email alerts are supported.
- Unlike other ETL tools, it provides fully customizable test algorithms and rules.
Cons of BigEval:
- Very limited options are provided in the free version.
- It does not provide proper customer support.
19. Matillion
Matillion is an ETL tool specially designed for businesses in the various cloud data side. It allows one to perform ETL operations simply. It helps in building data pipelines in no time and helps in efficiently connecting to data sources on cloud platforms. We can rapidly integrate and transform data for analysis by this platform that offers speed, and storage for its customers.

Pros of Matillion:
- It provides more than 60 data sources for integration.
- It helps to prepare data efficiently for analytics and visualization.
- Instant email alerts and SNS alert functionality are available just like other ETL tools.
- It has support for all AWS technologies and the integration is also very smooth.
Cons of Matillion:
- There is a lack of flexibility in the scaling model.
- Version updates are not backward compatible, so whenever a new version is updated lot of re-work is required.
- The cost of Matillion is expensive as infrastructure cost is also added to Redshift cost. If your organization is cutting costs then other ETL tools might help you to save up.
- The user interface can be simplified to enable users to get familiar with the product in a short period.
20. Azure Data Factory
Azure Data Factory is a serverless data integration platform that simplifies the ETL process. It is built on a pay-as-you-go model that makes it more cost-effective and scalable. It offers both no-code and code-based interfaces proven to be beneficial for people having less technical acumen. It provides around 90 built-in connectors and has support for GIT version control.

Pros of Azure Data Factory:
- Output formats such as PDF and CSV are supported.
- Instant Email, SMS, and Azure app push alerts are provided.
- No maintenance is required for ETL and ELT pipelines.
- It is easy to set up in Azure Data Factory with proper documentation it facilitates users to get started on their own.
Cons of Azure Data Factory:
- Integrations with non-Azure services are very limited.
- Only limited roles can be assigned to the platform.
- Flattening the complex JSON data, especially during mapping nested attributes is quite a tedious task.
- The details of the error are not specific and clear and error flagging is also not accurate as provided by other ETL tools in the market.
- No built-in pipeline exit activity is present in case of any pipeline failure.
21. Informatica PowerCenter
Informatica PowerCenter provides a high-performance, scalable data integration solution that supports the entire data integration lifecycle. PowerCenter can easily deliver various data integration solutions on-demand which includes batch, real-time, or Change Data Capture (CDC). It is also capable of managing the broadest range of data integration initiatives as a single platform.

Pros of Informatica PowerCenter:
- The development and maintenance of code is very simple in Informatica Power Center.
- It has diverse solutions to handle data quality problems and has various supporting tools as well.
- Customer support is very efficient and provides solutions to all queries efficiently.
- It provides connectivity to a large number of database systems providing flexibility to its users.
- Informatica Power Center performs well even when working with a large amount of data.
Cons of Informatica PowerCenter:
- Data Integration is unavailable for MacOS. If your business uses Apple machines, other ETL tools should be used.
- PowerCenter is a heavy software its memory utilization is very high and it even crashes when the required resources are not present.
- The platform performance with ODBC drivers is comparatively slow and time-consuming.
Conclusion
Based on the factors discussed above, modern businesses with high data volumes must choose an ETL tool for a smooth data analysis journey. Based on our requirements, we can leverage the benefits of any ETL tools mentioned above. However, suppose you are looking for an easy-to-use, reasonable pricing, secure, highly scalable, cloud or on-premise hosting with customized support, cloud or on-premise servers. In that case, Sprinkle should be at the forefront of any business leader.
Sprinkle Data has over 100+ built-in connectors that quickly scale with your business requirements. Its no-code interface allows anyone to ingest data from multiple data sources into your preferred data warehouse. Then, SQL-based or Python-based transformations are facilitated to reach your final business goal.
Frequently Asked Questions FAQs- Best ETL Tools
What is ETL and its tools?
ETL stands for Extract, Transform, Load, which is the process of pulling data from various sources, recasting it into a consistent format, and loading it into a target data warehouse. Some popular ETL tools include Sprinkle Data, Informatica PowerCenter, and Talend Open Studio.
Which tool is best for data integration?
The best data integration tools are Sprinkle Data, Pentaho Data Integration (PDI), Hevo Data, and integrate.io.
What is an ETL example?
An example of ETL is extracting customer information from multiple sources like CRM systems and website logs, transforming the data to create a unified customer profile with standardized attributes, and loading it into a data warehouse for analysis and reporting purposes.
What is ETL in SQL?
ETL in SQL refers to using SQL queries or scripts to perform extract-transform-load operations on data stored in relational databases.
Is Python an ETL tool?
Python is not specifically designed as an ETL tool but can be used effectively for performing ETL tasks due to its versatility, extensive libraries for data manipulation (e.g., pandas), and integration capabilities with various databases and file formats.
Is ETL an API?
ETL (Extract-Transform-Load) is not an API but rather a methodology or process for moving and manipulating data between systems.
Who uses ETL tools?
ETL tools are primarily used by Data Engineers, Data Analysts, Data Scientists & Business Intelligence professionals who need to integrate disparate datasets from multiple sources quickly & accurately across their organizations routinely for operational reporting & analytics applications.
Why is ETL used?
ETL (Extract, Transform, Load) is used in data integration processes to extract data from various sources, transform it into a format that is suitable for analysis or reporting, and load it into a destination such as a data warehouse.
What is the easiest ETL tool?
Some popular options known for their user-friendly interfaces include Sprinkle Data, Talend Open Studio, Microsoft SQL Server Integration Services (SSIS), and Apache NiFi.
Is Excel an ETL tool?
Excel is not typically considered a dedicated ETL tool, as its primary function is as a spreadsheet application for organizing and analyzing data.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}