

.png)
From CRMs to emails to spreadsheets, storing data values across multiple pipelines is common for tech-enabled businesses today. However, the scattered nature of the data makes it hard to analyze and use for decision-making. To make the data ready for analysis, pulling it together into a single repository becomes essential.
That's where ETL steps in.
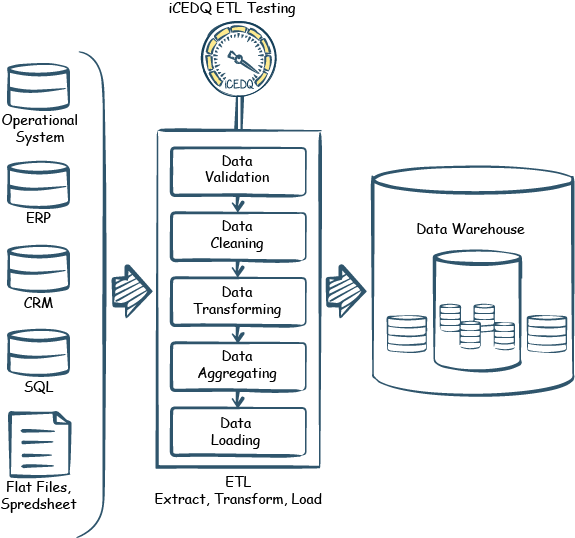
ETL, or Extract, Transform, and Load, is the process that helps to extract data from multiple pipelines, transform the information into a consistent data type, then load it into a single repository.
ETL testing helps you to be sure that the data transferred from the different pipelines to the central repository occurs with strict adherence to transformation rules and is in compliance with all validity checks.
This guide goes over the basics of ETL testing, the steps involved in the process, and how you can use it to create a unified data repository.
The data in the warehouse is often the only source a business uses for analysis and decision-making. This means that centralized data should be accurate and reliable. It should also represent all information from the various pipelines.
Since the source data is in various formats and undergoes ETL, there is a possibility of errors that reduce the quality and accuracy of the integrated data. We put the data through the ETL testing process to prevent or correct this.
ETL testing ensures the data is correctly extracted, transformed, and loaded into the target warehouse. It helps identify any existing or potential errors, debug them on time, and ensure that the ETL process continues running smoothly. By running the testing process, you can also ensure that none of the data is lost during the extraction and transformation process.
Usually, both ETL and the testing process are carried on simultaneously. Consider an example to understand what is ETL testing.
Example
You run an electronics company spread across various cities. You want to launch a new product and collect customer data.
Your first sources will be the structured data within the company: payment information, order IDs, and phone numbers. You also include unstructured information such as customer reviews, feedback, and social media images.
To predict the outcome of your product launch, you need to integrate all the data into a unified platform. This is where the ETL process comes in. Through the process, you gather all structured or unstructured information and unify it in a single warehouse. Further, you test the ETL process to ensure no data gets left out and the process continues to run smoothly.
Based on the data warehouse, you can generate endless reports and analytics to aid business decisions.
.png)
What is ETL Testing Used For?
The ETL process is a series of codes used to ensure the seamless aggregation of data. And like any other piece of code, the ETL process must also be tested for bugs. While the testing is essential during initial implementation, there are other use cases too, such as:
- Setting up a new unified data repository
- Transferring bulk amount of data
- Continually loading data into the target warehouse
- Preventing duplication or deletion of data from multiple sources
- Including additional data pipelines other than the existing sources
- Moving from legacy systems to modern systems
- Revamping software, including integration, upgradation, or scaling
- Correcting suspected errors in the ETL process, such as missing data, reduced quality, incorrect formatting, and so on
ETL Testing: Case Studies
mPokket, a student loan app, used transactional databases built on MySQL and the Cockroach database. These databases were also used for business intelligence. As the app grew in popularity, the existing databases were insufficient to scale up. The app also wanted to aggregate historical data to make predictive analyses.
To move their data, mPokket used Sprinkle and built an ETL process to load it into the Hive warehouse. Through continuous testing, the app could aggregate historical data in Hive. It could also continually upload new customer information to the target data warehouse.
Similarly, another SaaS brand, Netenrich, used Sprinkle to build an ETL process for moving data into the Bigquery warehouse. The data, spread across several pipelines, is extracted and loaded from time to time. With proper ETL testing, they can load up to 1 million rows of data every single day.
Types of ETL Testing
Different types of ETL tests are executed at each step of the ETL process. These can be broadly grouped into four types: new system testing, migration testing, change testing, and report testing. Depending on the steps, testers carry out any of the following tests.
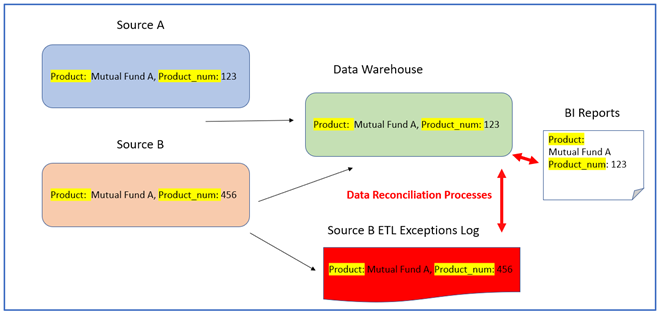
1. Product Reconciliation
This test verifies the order and logic of the data as it is loaded into the production systems. It safeguards the systems from data errors, non-compliance, or faulty schema.

2. Source to Target Validation
A data validation test is carried out to check if the data from source systems matches the data loaded in the target warehouse. This can include data warehouse testing or database testing.

3. Completeness Testing
This test ensures that all the data from the source is loaded into the target without duplicate data or loss.
4. Transformation Testing
As several transformation rules are applied to one type of data, this test makes sure all the data has consistently transformed according to the rules.
5. Accuracy Testing
After data transformation, the data is verified for accuracy. The formats and schema of the data may change, but the quality and information should remain intact.
Though there are several types of ETL testing, all of them follow a general process given below.
The ETL Testing Process

To understand ETL testing, you need a thorough understanding of the steps involved. The ETL testing process consists of eight steps that ensure the smooth functioning of the ETL process.
These steps are usually performed in order but can be repeated a few times to ensure the process is error-free. These are the important steps involved in the ETL testing process:
1. Assessing business requirements
This is a preliminary step to identify the scope of the ETL testing process. Testers can create a plan for further data integration only after gauging the business requirements. Through this step, testers achieve three important targets:
- Identify data sources, types, and formats for integration
- Build transformation rules for the data and select the types of ETL testing
- Identify a target warehouse for loading
2. Verifying data sources between source and target
This step is crucial to check the validation of sources and to gauge the success of the testing process later. By verifying data sources, testers create a record for existing sources to prevent duplicity of data and run source-to-target validation tests to eliminate any loss of information.
3. Designing and executing test cases
Using the ETL process directly on source data is risky as the data is often sensitive. Instead, testers generate synthetic data to run the process, debug it, and prepare the process for better compliance with the source data. These test cases can be prepared manually or through test data generation tools.
4. Extracting data from business systems
Extracting is the first step in the ETL testing full form. Once the test cases are successful, testers can move on to the sources. Testers must exercise caution during the data extraction step and ensure that all data is completely transferred. Due to the variety of formats and structures, data is prone to be lost during extraction.
5. Performing data transformation for data quality testing
Though the source data has various formats, it should be compatible with the target unified repository. To ensure this, testers put the data through formatting rules while keeping the quality and content in check.
6. Loading data into the selected warehouse
Loading the data after transformation completes the ETL process, but it still requires rigorous testing. The data can be loaded in batches or at once depending on business requirements. After the upload is complete, testers need to verify the data for accuracy and reliability. This is done through the source-to-target validation checks using the primary reports generated in Step 2.
7. Testing and preparing Reports
Once the ETL process concludes, testers still need to ensure the error-free continuity of the process. If the ETL testing detects any existing errors, or if new data sources are introduced, repeat the steps from 4 to 6 and fix errors by performing regression testing.
8. Submit the closure report
Concluding the ETL testing means submitting a closure report. The closure report contains the testing steps, primary findings, and detected bugs. It also suggests fixes and further recommendations to continue the testing process. Submitting this report helps the business evaluate its ETL process and keep track of errors for future reference.
These eight steps are a general process for ETL testing. However, depending on specific goals, testers can modify or include additional steps or use different types of ETL testing.
Conclusion
For any business, data analysis and, in turn, ETL is essential. Through this guide, we answer “What is ETL testing?” by introducing the concepts of ETL and giving an extensive overview of the process involved. Using reliable ETL testing tools and software such as Sprinkle Data helps you build and implement a seamless ETL process along with the right testing process.
For more information on Sprinkle, check out our products.
Frequently Asked Questions (FAQs)
Is SQL required for ETL testing?
Yes, ETL testing may require SQL as the process itself involves several SQL queries when validating data. However, other methods such as interfaces and tools can be used to complete the ETL testing process without SQL.
Does ETL testing require coding?
ETL testing originally required a lot of coding. But with a no-code ETL tool, you can easily automate the ETL testing process without the hassle of writing complex ETL tools.
Which tool is used for ETL testing?
You can use tools such as Sprinkle Data to perform ETL testing. Sprinkle Data is a no-code platform that helps with data transformation and integration, simplifying the ETL testing process with accuracy.
What is ETL testing with example?
ETL testing stands for Extract, Transform, and Load testing, which involves validating the data extraction, transformation, and loading processes in an existing data warehouse or data integration system. For example, in ETL testing, testers ensure that data quality is maintained and is extracted correctly from the source system, transformed accurately according to business rules, and loaded into the target database without any loss or corruption.
Is ETL testing is manual testing?
ETL testing can be both manual and automated. Manual testing involves testers manually verifying data transformations and loading processes by executing test cases. Automated testing involves using tools to automate the ETL testing process.
Does ETL testing have a future?
ETL testing has a promising future as organizations continue to adopt big data technologies and invest in data integration solutions. With the increasing volume of data being generated daily, the need for accurate and efficient ETL processes will only grow in importance.
What knowledge is required for ETL testing?
To get started with ETL Testing one needs basic knowledge of databases including SQL queries Scripting language might also be beneficial depending upon the specific tool you are using Familiarity with big-data concepts would also be advantageous
Which is the easiest ETL tool to learn?
Some popular easy-to-learn ETL tools include Talend Open Studio Express Edition which comes with an intuitive interface drag-and-drop functionality Another user-friendly option is Apache Nifi which simplifies building a scalable data model through visual programming
Is ETL testing in demand?
Yes! With companies recognizing the value of acquiring actionable insights from vast amounts of structured unstructured big data The demand for professionals possessing skills related to managing to cleanse and integrating massive datasets through robust end-to-end ELT/ETL frameworks continues to rise exponentially
What is the future of ETL tester?
The future looks bright for individuals specializing in performing quality assurance activities associated with Extract/Landing Transformation Loading operations within diverse environments Tools methodologies enabling quick flexible execution verification comprehensive validation procedures play pivotal roles in facilitating better decision-making








{kind=link}
{kind=link}
{kind=link}