


Data models are a crucial component in data management and analytics. But what exactly are data models and why are they so important?
In this blog post, we will explore data models and some data modeling techniques.
A data model is essentially a blueprint that defines how data is structured, stored, and accessed within a database. It provides a way to represent the logical data structures and establishes relationships between data.
Data Modeling techniques
1. Entity relationship modeling

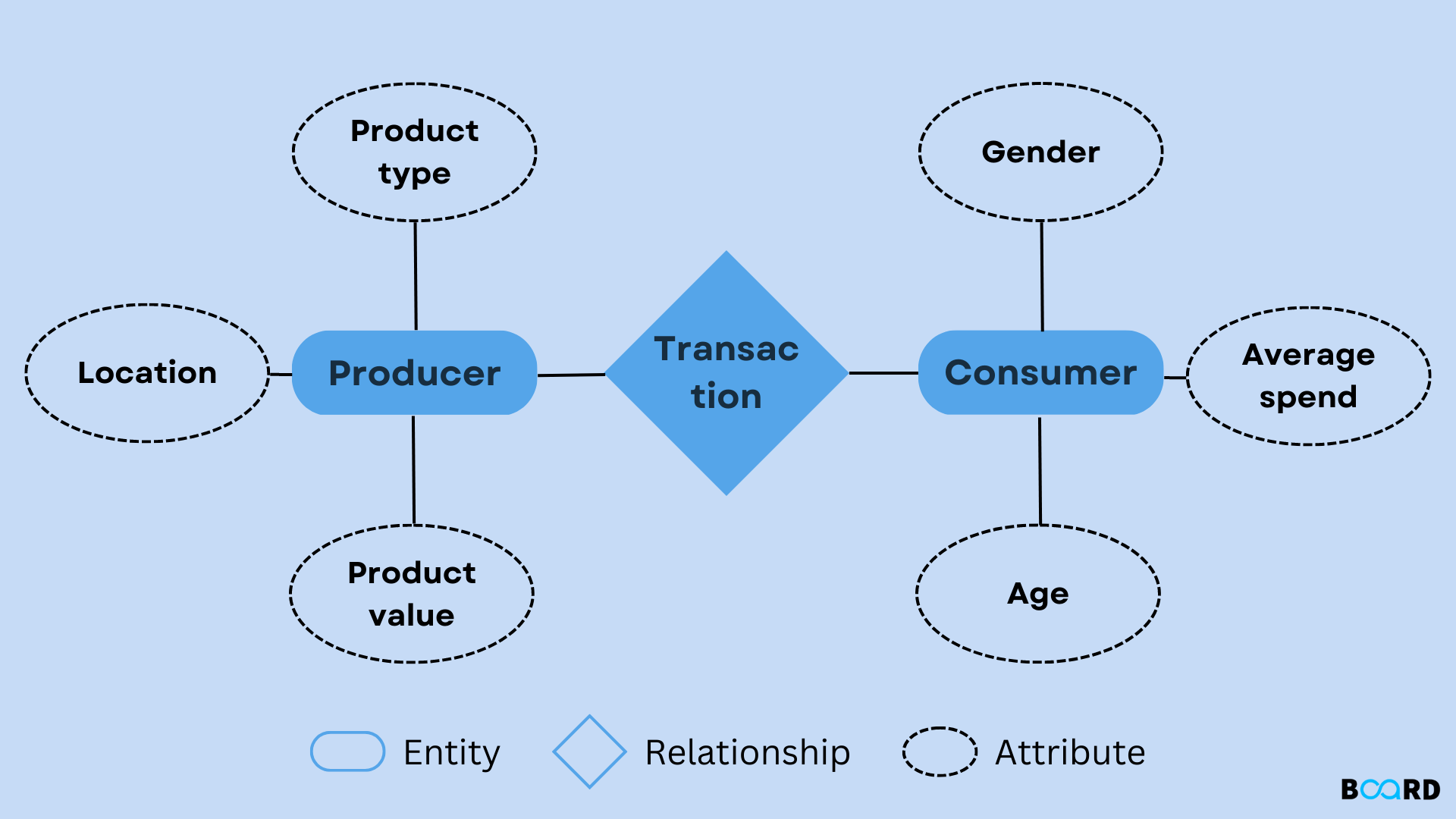
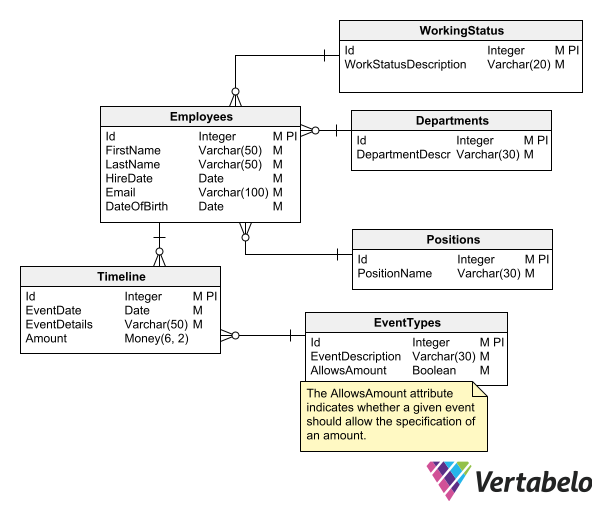
Entity relationship modeling, also known as ER modeling, is a method used to visually represent the relationships between entities in a database. An entity is anything that can be identified as distinct and separate from other entities, such as a person, place, object, event, or concept. Relationships define how these entities interact with each other and are represented by lines connecting the entities in an ER diagram.
In an ER diagram, entities are represented as rectangles with their names written inside them. Each entity has attributes that describe its characteristics. Relationships between entities are depicted using diamonds connected by lines to the related entities. These relationships can be one-to-one, one-to-many, or many-to-many.
Steps in Entity Relationship Modeling
The process of entity-relationship modeling involves several steps:
- Identify Entities: The first step is to identify all relevant entities in the domain being modeled.
- Define Attributes: For each entity identified, define its attributes that describe its properties.
- Establish Relationships: Determine how different entities are related to each other and specify the type of relationships.
- Create an ER Diagram: Use symbols like rectangles for entities, diamonds for relationships, and lines to connect them to create an ER diagram that visually represents the structure of the database.
- Normalize Data: Ensure that the model follows normalization principles to eliminate redundancies and improve efficiency in data storage.
2. Relation Modeling
Relational modeling is a key concept in database management that involves creating relationships between different entities or tables within a database.
In a relational model, data is stored in tables with rows and columns. Each table represents a specific entity or object, such as customers, products, or orders. The relationships between these tables are established through keys, which are unique identifiers for each record in a table.
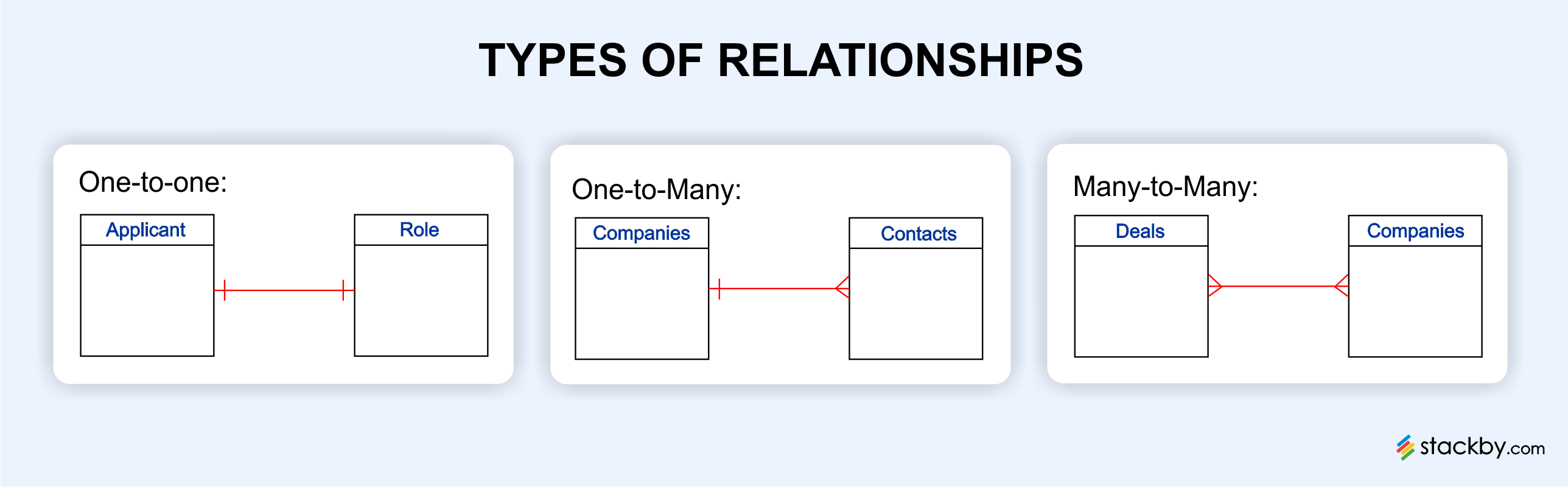
Several types of relationships can be defined in relational modeling:

- One-to-One: In this type of relationship, each record in one table is related to only one record in another table.
- One-to-Many: In this type of relationship, one record in one table can be related to multiple records in another table.
- Many-to-Many: In this type of relationship, multiple records in one table can be related to multiple records in another table.
To establish these relationships, keys are used to link the tables together. There are two main types of keys used in relational modeling:
- Primary Key: A primary key is a unique identifier for each record in a table.
- Foreign Key: A foreign key is a field in one table that references the primary key of another table.
3. Object-oriented model - OOM

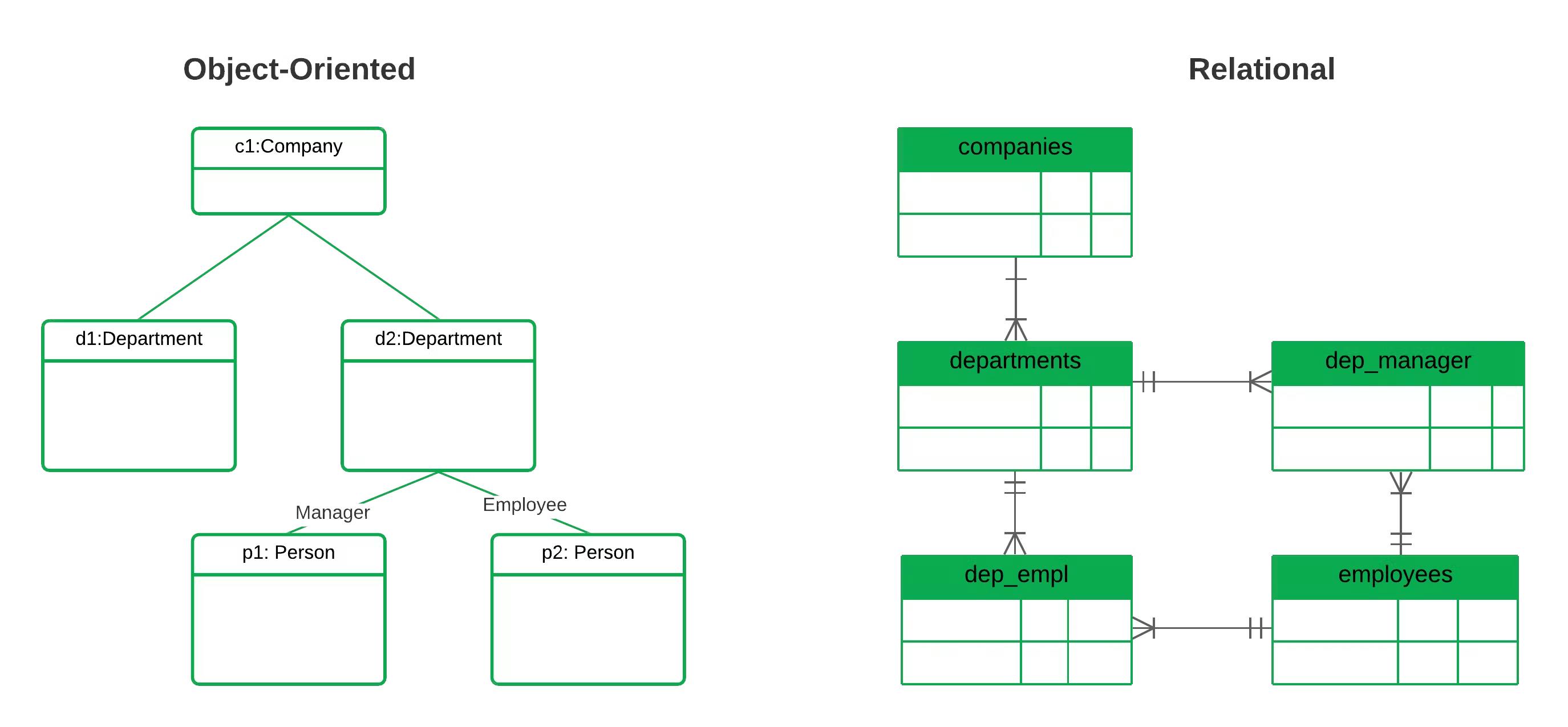
Object Oriented Modeling (OOM) is a popular approach used in software development to create models based on real-world objects. It is a key aspect of Object Oriented Programming (OOP), which focuses on designing software systems that are organized around objects rather than actions and logic.
In OOM, developers identify the key entities or objects in a system and define their attributes and behaviors. This approach helps break down complex systems into manageable components, making it easier to understand and maintain the codebase.
There are several key concepts in OOM that developers should be familiar with:
- Classes: In OOM, classes are templates for creating objects. They encapsulate data (attributes) and behavior (methods) related to a specific entity or concept.
- Objects: Objects are instances of classes that contain specific values for their attributes.
- Inheritance: Inheritance allows one class to inherit attributes and methods from another class. This promotes reusability and reduces code duplication.
- Polymorphism: Polymorphism allows different classes to be treated as instances of a common superclass. This enables developers to write more flexible and reusable code
- Encapsulation: Encapsulation refers to the practice of bundling data (attributes) and behavior (methods) within a single unit (class).
4. Data Flow Diagram

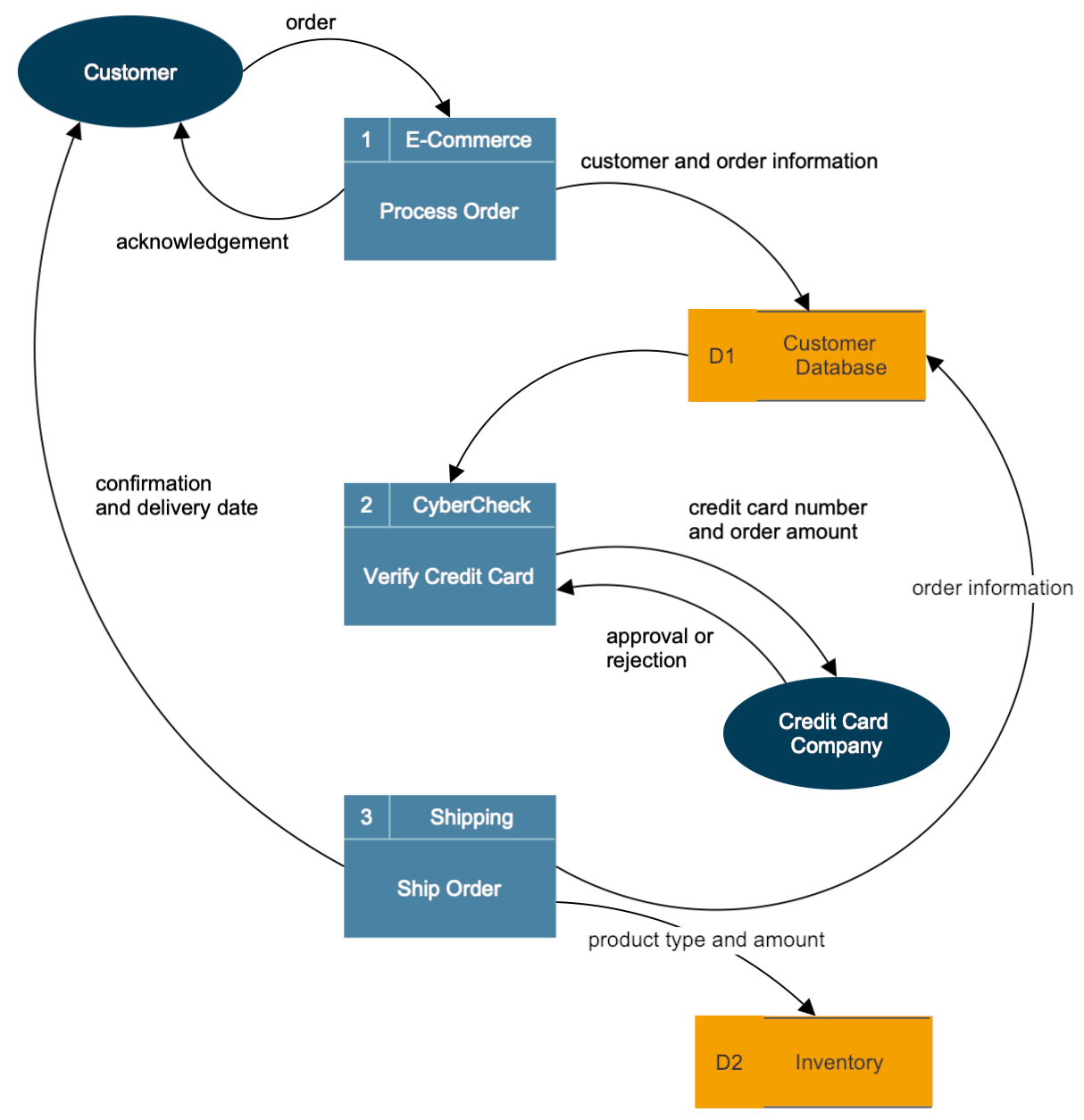
A data flow diagram is a graphical representation of the flow of data within a system. It shows how information is input into the system, processed or transformed by various processes, stored in files or databases, and output to external entities such as users or other systems.
DFDs use symbols such as circles (representing processes), arrows (representing data flows), rectangles (representing data stores), and parallelograms (representing external entities) to represent different components of the system and their interactions.
How to Create a Data Flow Diagram
Creating a data flow diagram involves several steps:
- Start by identifying all the key processes, data stores, external entities, and data flows within the system.
- The context diagram is the highest level of abstraction in a DFD and shows the interactions between the system under study and its external entities.
- The level 0 diagram provides an overview of the entire system by showing all major processes and their relationships with each other.
- Break down complex processes into smaller subprocesses until you reach a level where each process can be easily understood.
- Once you have decomposed all processes to an appropriate level, add additional details such as data store names, file structures, or specific data elements flowing between processes.
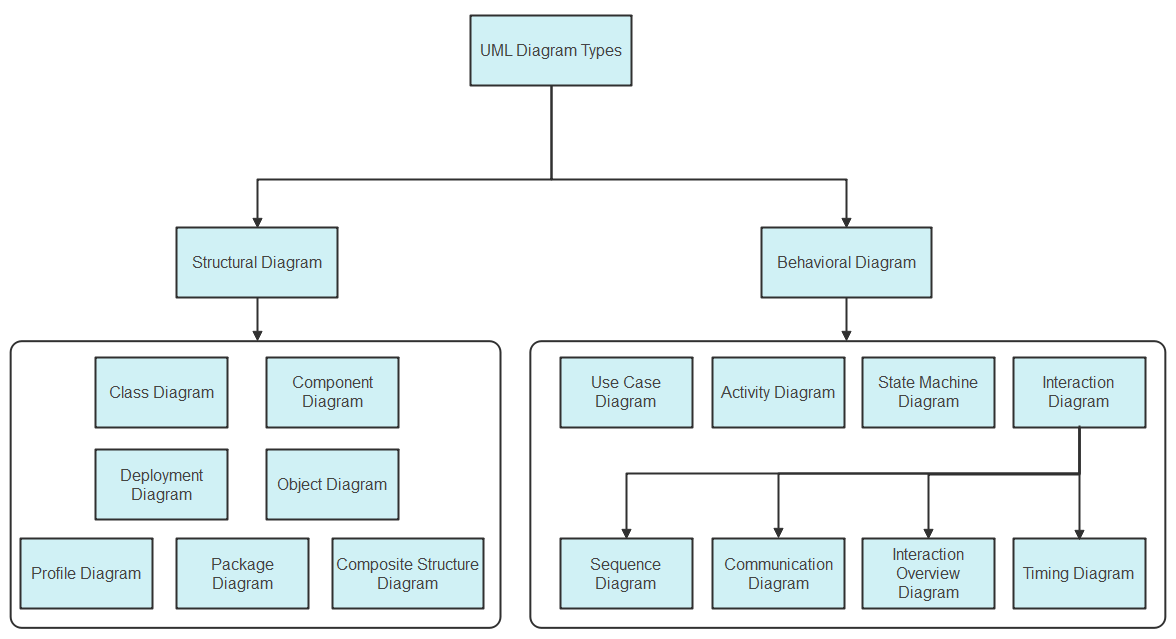
5. Unified Modeling Language (UML)

Unified Modeling Language (UML) is a standardized modeling language used in software engineering to visually represent a system's design. It provides a common language for developers, designers, and stakeholders to communicate and understand the structure and behavior of a system.
Several types of UML diagrams can be used to represent different aspects of a system:
- Class Diagram: Class diagrams depict the classes in a system and their relationships with each other.
- Use Case Diagram: Use case diagrams describe how users interact with a system by representing the different use cases or scenarios in which they interact with the system.
- Sequence Diagram: Sequence diagrams illustrate the interactions between objects or components in a specific scenario or sequence of events.
- Activity Diagram: Activity diagrams represent workflows or business processes within a system.
- State Machine Diagram: State machine diagrams model the states of an object or component and how it transitions from one state to another based on events or conditions.
- Component Diagram: Component diagrams show the physical components of a system and how they are interconnected.
- Deployment Diagram: Deployment diagrams depict the physical deployment of software components onto hardware nodes such as servers or devices.
6. Dimension Modelling

Dimensional modeling is a data modeling technique used in data warehousing to structure and organize data for easy retrieval and analysis. It involves organizing data into dimensions, which represent the different ways that users want to view their data, and facts, which are metrics that users want to analyze.
Here are some key points about dimensional modeling:
Dimensions: Dimensions are the descriptive attributes of data that provide context for analysis. They are typically hierarchical, with levels ranging from broad categories to specific details.
Facts: Facts are the numerical measurements or metrics that users want to analyze about dimensions. These can be quantitative measures such as sales revenue, quantity sold, or profit margin.
7. Data Vault Modeling

Data vault modeling is a methodology used in data warehousing that provides a flexible and scalable approach to storing and organizing data. It consists of three key components: hubs, links, and satellites.
- Hubs: Hubs are the core building blocks of a data vault model. Each hub contains a unique list of business keys that identify the entity it represents. Hubs act as central repositories for related data and serve as integration points for linking other entities together.
- Links: Links connect hubs by establishing relationships between them. Links contain foreign keys from multiple hubs and help maintain referential integrity across the model. By creating links between hubs, organizations can easily navigate complex relationships within their data.
- Satellites: Satellites store additional attributes or context-related information about hubs or links. They capture historical changes to the data over time and provide a detailed audit trail of all modifications made to the model.
8. Graph Data Modeling

Graph data modeling is a technique used in database design that involves representing relationships between entities as nodes and edges. This approach is especially useful for modeling complex relationships in data sets where traditional relational databases may not be sufficient.
Here are some key points to consider when working with graph data modeling:
- Nodes: In graph data modeling, nodes represent entities or objects in the data set.
- Edges: Edges in graph data modeling represent relationships between nodes.
9. Document Modeling

Document modeling involves the creation and maintenance of structured documents that contain important data and information for business processes.
In document modeling, the goal is to design documents in such a way that they accurately represent the underlying data and provide a clear structure for organizing and retrieving information. This typically involves defining the types of documents that will be used, specifying the fields or attributes that each document can contain, and establishing relationships between different types of documents.
- Documents Structure: One common approach to document modeling is to use a schema language such as XML or JSON to define the structure of documents.
- Versioning: Documents often change over time and by implementing version control mechanisms, organizations can ensure that users have access to the most up-to-date information while still being able to refer back to previous versions if needed.
- Search Capabilities: By structuring documents with well-defined fields and relationships, organizations can more easily index their content and enable efficient search queries.
10. Key Value Modeling

Key-value modeling is a data modeling technique that represents data as a collection of key-value pairs. It is a simple and flexible way to organize and store data, allowing for easy retrieval and manipulation.
In key-value modeling, each piece of data is stored as a key-value pair where the key is a unique identifier that points to the corresponding value. This allows for quick access to specific pieces of data without having to search through a large dataset.
Data Modeling Best Practices
- Before starting the data modeling process, it's important to have a clear understanding of the business requirements and objectives.
- When creating data models, use standard notation such as Entity-Relationship Diagrams (ERDs) or Unified Modeling Language (UML).
- Normalize your data by breaking down large tables into smaller ones to eliminate duplicate data.
- Use descriptive names for tables, columns, and relationships to make it easier for others to understand your data model.
- Make sure to document each aspect of your data model, including assumptions made during the design process.
- Keep track of changes made to your data model by using version control systems like Git or SVN. This will help you track changes over time and revert to previous versions if needed.
- Optimize query performance by creating indexes on columns frequently used in queries and consider using materialized views for complex aggregations.
- Use constraints like primary keys, foreign keys, unique constraints, and check constraints to enforce data integrity rules at the database level.
- Minimize the use of NULL values in your database schema as they can lead to unexpected behavior during query execution.
- Consider using surrogate keys like auto-incrementing integers as primary keys instead of natural keys to simplify joins between tables
- While normalization is important for reducing redundancy, avoid over-normalizing which could lead to overly complex queries.
By following these best practices, organizations can create well-designed databases that meet their specific needs while also being scalable, easy to maintain, and highly performant
Features in a data modeling tool
With so many data modeling tools available on the market, it can be overwhelming to choose the right one for your business needs. In this section, we will discuss features of data modeling tools that you should consider when selecting a tool for your organization.
- User-friendly interface: The user interface should be intuitive and easy to navigate, allowing users to quickly create and modify database designs.
- Database support: Look for a data modeling tool that supports multiple database management systems (DBMS) such as MySQL, Oracle, SQL Server, and PostgreSQL.
- Collaboration capabilities: Features like real-time editing and commenting should be available in the data modeling tool.
- Version control: Look for a data modeling tool that offers versioning capabilities, allowing users to revert to previous versions if needed.
- Data visualization: Visualizing complex relationships between entities in a database can be challenging without the right tools. Look for a data modeling tool that offers a visual representation of data.
Sprinkle Data to the rescue!
Sprinkle Data stands out as the best option for organizations looking for a comprehensive data modeling tool with enhanced BI capabilities. Its intuitive interface, modeling capabilities, visualization, and advanced analytics capabilities, make it a top choice for businesses of all sizes.
Frequently Asked Questions FAQs- Data Modelling Techniques
What is a data model?
A data model is an abstract representation of how data is organized and stored within a database system.
What are the top 5 data modeling techniques?
The 5 data modeling techniques are
- conceptual data modeling,
- logical data modeling,
- physical data modeling,
- dimensional data modeling, and
- hierarchical data modeling.
What are the 3 basic data modeling techniques?
The three basic data modeling techniques are conceptual logical and physical models
- Conceptual data model: The conceptual model involves capturing high-level business concepts and requirements without going into technical details
- Logical data model: Logical data models focus on defining the structure of the database based on the business requirements and rules.
- Physical data model: The physical model translates the logical model into a specific database implementation, considering performance optimization and storage considerations.
What is the data modeling process in SQL?
Data modeling in SQL refers to designing the structure of databases using SQL (Structured Query Language). It involves creating tables with appropriate columns, constraints, relationships between tables, indexes for faster query performance, and other database objects as needed to store and manage information efficiently.
What are the 4 types of models in DBMS?
The four types of models in DBMS are hierarchical model, network model, relational data model, and object-oriented model. Each type represents a different approach to organizing and structuring data within a database management system.
What are the three types of data models used today?
Types of Data Modeling include Entity-Relationship Models (ER Models), Object-Based Data Models, Object-Oriented Data Models, and Semi-structured Data Models.
Why is data modeling important?
Data modeling plays an important role in creating structured representations of real-world situations or systems for better understanding, analysis, decision-making, and communication among stakeholders involved in software development projects. It helps identify key entities, determine relationships between them, and establish rules governing these relationships
What is an example of data modeling?
An example of Data Modelling could be creating an ER diagram that shows how different entities like customers, purchases, and products are related in an e-commerce application.
What are the applications of the data model?
Applications of Data Modelling include Database Design, Systems Analysis, Business Process Management, data analysis machine learning, etc which help businesses understand their operations, facilitate effective decision-making, and improve overall efficiency through optimized use of available resources.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}