


In today’s world where data is considered to be the most valuable company’s asset, there is a need to protect it from data breaches and damages. As we know with every problem comes a solution, so for this issue we have modern data warehouses with the best built-in functionalities to protect it from attacks and are used to manage the data effectively, one such warehouse is: Google BigQuery.
What is Google BigQuery?
Google BigQuery is a serverless, fully managed enterprise data warehouse. It utilizes BigTable and the Google Cloud Platform and is able to join, query, and analyze data of any size, from a few rows to petabytes, in just a few seconds.
BigQuery is not designed for transactions, so it's not suitable for OLTP (Online Transaction Processing). A simple query of 'SELECT * FROM bigquery-public-data.object LIMIT 10' on a 100 KB table with 500 rows takes about 2 seconds, so it's for Big Data tasks only.
BigQuery is user-friendly and beginner-friendly, thanks to its support of SQL-like queries. You can access it through its web UI, command-line tool, and client libraries (C#, Go, Java, Node.js, PHP, Python, and Ruby). Alternatively, you can use its REST APIs and submit a JSON request to get your job done.
Many firms use this data warehouse to implement data analytics use cases to help them make better-informed decisions. It is a highly scalable and cost-effective data warehouse that supports many features directing businesses to progress in the right direction.
Features of BigQuery
BigQuery is a fast, cost-efficient serverless data warehouse for organizations with massive data needs. It provides detailed insights via built-in Machine Learning, and analysis of petabytes of data through ANSI SQL. Let's explore some of its features.
Multicloud Functionality (BQ Omni)
- BigQuery can process data in its existing location [across cloud offerings], eliminating the need for data transfer.
Built-in ML Integration (BQ ML)
- BigQuery ML enables you to create and run Machine Learning models utilizing straightforward SQL queries.
Foundation for BI (BQ BI Engine)
- BigQuery BI engine is an in-memory analysis system that quickly analyzes data stored in BigQuery with sub-second response times and high concurrency.
Geospatial Analysis (BQ GIS)
- BigQuery's GIS capability enables the use of location and mapping information within your data warehouse. This is done by converting coordinates (latitude and longitude) into geographical points.
Automated Data Transfer (BQ Data Transfer Service)
- BigQuery Data Transfer simplifies the process of regularly syncing data into BigQuery: no coding required, managed by the analytics team.
Free Access (BQ Sandbox)
- Google's BigQuery Sandbox allows you to try its Cloud Console features without creating a billing account, project, or providing credit card details.
Though BigQuery is fast and affordable, it can consume much processing power if not used properly.
5 best practices to use Google BigQuery correctly:
- Selecting the correct Data format
- Using partitioning for better performance
- Using clustering for better performance
- Managing workloads using reservations
- Using logs the right way
1. Selecting the correct data format
For BigQuery ETL, there is a wide range of file formats that can help you in smooth data ingestion without any hassles. Proper data ingestion format should be the first and foremost thing to perform any data operations, and big query provides this flexibility by providing multiple data formats. Choosing the correct file format solely depends on one's requirements.
If your aim is to optimize the load pace then the Avro file format is most favoured. This is basically a binary row-based format that allows us to split data and then read it in parallel. Businesses prefer using Avro file format in compressed form which is supposed to be quicker in terms of magnitude as compared with the other techniques of ingesting data into big query.
Parquet and ORC are binary-based and column-oriented data formats that are relatively faster but are not as fast as loading data from Avro file formats.
Loading data from CSV and JSON compressed files is going to be more overhead and slower than loading data from any other formats as it takes more computation time. This is Because compression of Gzip is not breakable. First, it takes the Gzip file and then loads it onto a slot within the big query, then decompression of the file is done, and finally, it parallelises the load afterward. This process is a little slower and consumes more time hence impacting business agility.
The image below shows the file formats according to the speed of data loading.

2. Use of Partitioning for better performance
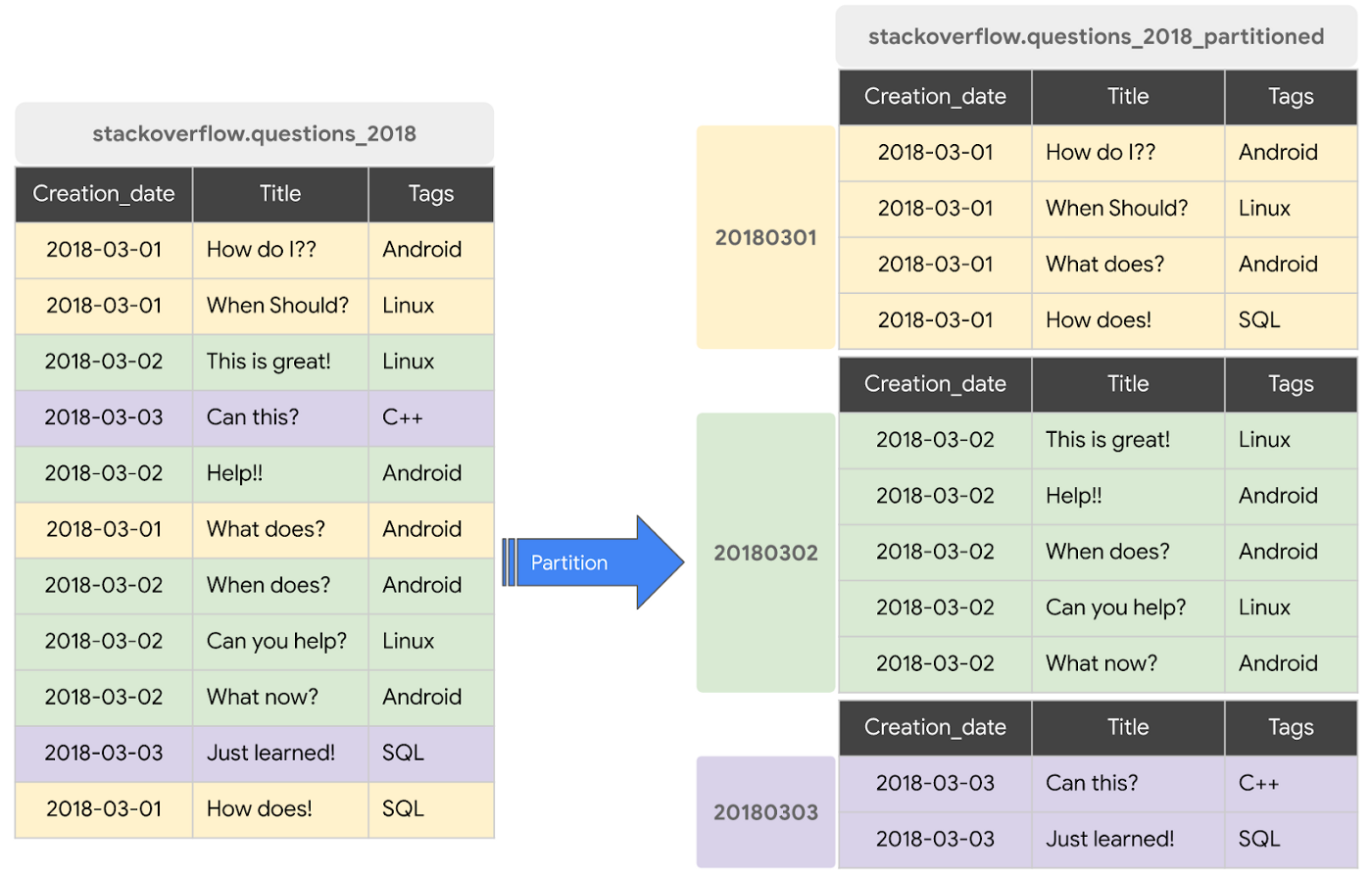
In BigQuery, partitions help in splitting the data on disk based on the ingestion time or on the basis of the column value of the data. It helps to divide large tables into smaller tables creating a partition. Data for each partition is stored singly associated with its own metadata for faster recognition. Partitioning can help enhance the query performance as when a query related to a specific partition value is run in BigQuery then it only scans the partition value that is provided instead of the entire table, saving time and enhancing query performance.
In partitioning, data is divided into smaller tables for low cardinality columns ie columns having few unique values like gender, boolean columns, etc that is proved to be time-efficient. Partitioning helps to keep costs down by avoiding the scanning of large amounts of data and also helps in storage optimization.
A good practice is whenever you are dealing with a fact table or a temporary table it is advised to utilize a partition column by specifying the partition key on the date dimension, it speeds up the query and provides optimal performance.

IMAGE SOURCE: Partitioning the table based on the date column.
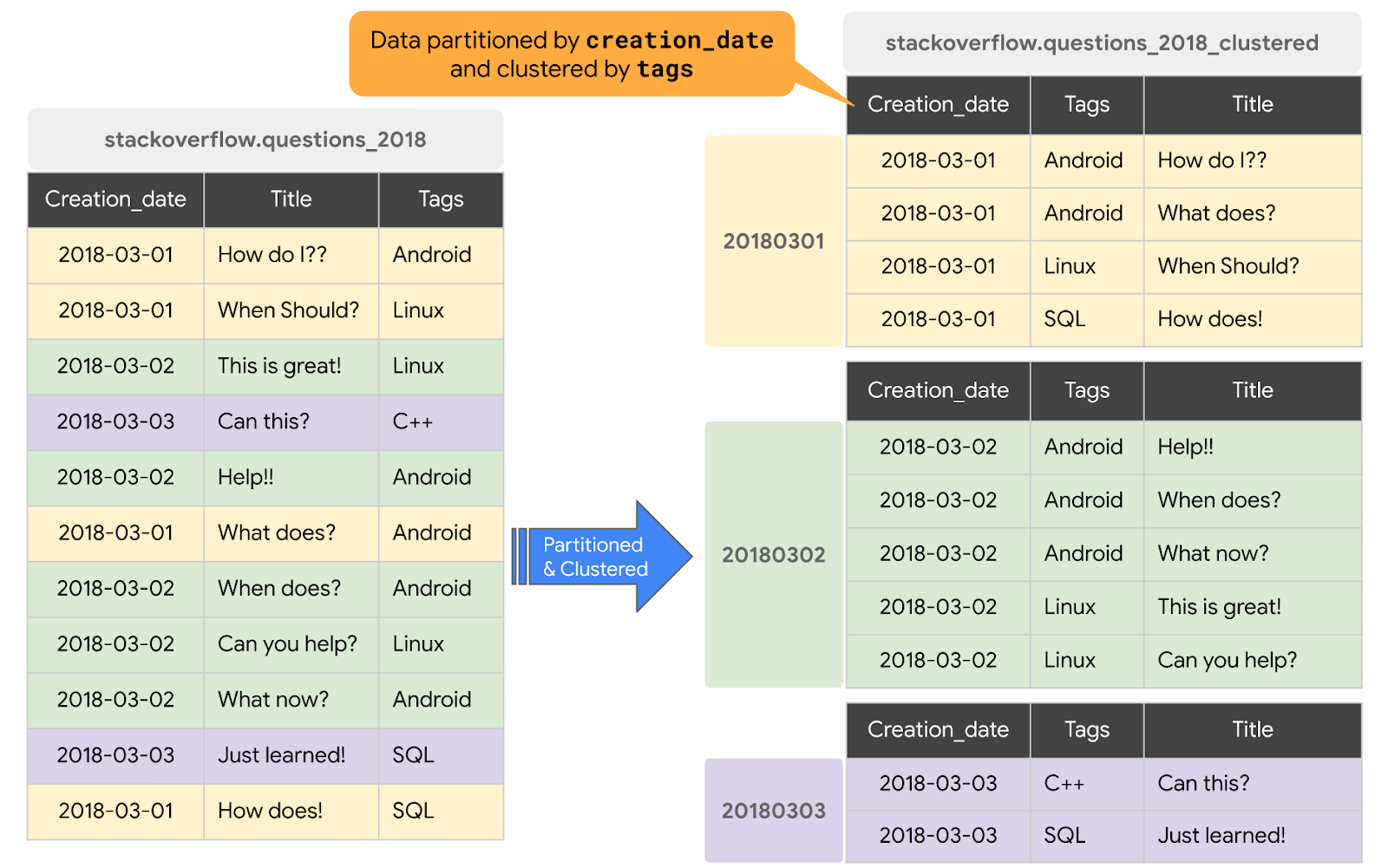
3. Use of clustering for better performance
Clustering is basically the ordering of data within a partition. Making a cluster allows BigQuery to keep similar data conjointly and boost performance by scanning just a few records when a query is run. If clustering is used the right way it can provide many performance-related benefits.
A good convention is to use clustering wherever possible as it will restrict the amount of data scanned per second. For example, let’s take a transaction fact table partitioned on the transaction date column, and adding clustering on columns like country, state, ID, etc will result in dynamic and time-efficient queries over that table.
A combination of partitioning and clustering used together is also highly recommended to optimize your query performance by identifying the low and high cardinality columns for partitioning and clustering.

IMAGE SOURCE: Data clustering done by tags column
4. Managing workloads using reservations
BigQuery reservations bring down the costs, are highly scalable, and provide great flexibility to switch between two pricing models to purchase slots:
1. On-demand pricing:
The default pricing model that gives up to 2000 concurrent slots.
2. Flat rate pricing:
Calculated slots are purchased and reserved according to requirements.
A slot is basically a virtual CPU used by BigQuery to execute SQL queries. The number of slots is automatically evaluated by BigQuery according to query size and complexity.
To prioritize a query reservations are preferred. In this, if a query has a higher priority then more slots should be assigned to it for quick response time and to effectively manage different workloads.

IMAGE SOURCE : Workload management using reservation.
5. Using logs the right way:
BigQuery keeps trace of all admin activities via log files and it is really beneficial if you want to perform an analysis of your system to keep a check on its proper functioning.
Basically, there are some good practices related to logs :
1. Export data access log files to BigQuery :
It is recommended to keep all your audit log files in a unified place as when all your log files are sitting together it becomes a lot easier to query on them.
2. Visualizing audit logs using data studio :
Visualizing the audit log files can actually help to track down the used resources and even monitor the amount of money spent on them.
This practice can really help in the following ways:
A. Monitor your spending patterns
B. Cost bifurcation by project
C. Making queries more efficient and less space-consuming hence can help in cutting down on cost

IMAGE SOURCE : Data studio for monitoring queries
Frequently Asked Questions - FAQs - 5 Best Practices For Bigquery ETL
Can BigQuery be used for ETL?
Yes, BigQuery can be used for ETL (Extract, Transform, Load) processes. It provides a scalable and serverless environment to process large amounts of data.
What is the ETL process in BigQuery?
The ETL process in BigQuery involves extracting data from various sources, transforming it into the desired format or structure, and loading it into BigQuery tables for further analysis or storage.
How to Build ETL Pipeline in BigQuery?
To build an ETL pipeline in BigQuery, you can use various tools and techniques such as Cloud Dataflow, and Cloud Dataprep, or write custom code using SQL or programming languages like Python or Java.
When should you not use Bigquery?
You should not use BigQuery when dealing with real-time data processing or low-latency requirements. BigQuery is designed for batch-oriented analytics workloads rather than transactional or operational tasks.
What are the limitations of bigquery?
Some limitations of BigQuery include high costs for frequent small queries, limited support for complex transactions, and restrictions on nested data structures.
Which database language is most used in ETL?
SQL is the most commonly used database language for ETL processes due to its simplicity and wide adoption among developers and analysts.
What are some Bigquery Optimization techniques?
Some BigQuery optimization techniques include partitioning tables based on date or other criteria, clustering tables to improve query performance, and optimizing schema design to minimize data shuffling during query execution.
How to perform user access management in BigQuery?
User access management in BigQuery can be performed through IAM roles and permissions. You can assign specific roles to users or groups to control their access levels and actions within the BigQuery project.
What are some best practices in Bigquery?
Best practices in BigQuery include optimizing query performance by using appropriate table structures and indexes, controlling costs by managing query usage and storage resources efficiently, and monitoring query statistics for identifying bottlenecks or optimizations.
How to control cost in BigQuery?
To control cost in BigQuery always avoid using SELECT * statements, before executing a query always estimate its cost and always keep an eye on the visualization and query edit logs for accurate cost estimations.








{kind=link}
{kind=link}
{kind=link}