

Introduction

Data is the new norm when it comes to adapting to new technology and innovations. It happens to be the “Mya” of innovations and acts as leverage in having a jump-start ahead of the competitors in the industry.
However, few enterprises find it difficult to derive actionable insights as there happen to be discrepancies between the organization's goal and the quality of data they produce. This is where DevOps first came into place, solving organizational problems with technical solutions i.e. bringing together people who build software to people who develop and run it.
This solved one side of the problem but as big data emerged, millions of records were collated of which few were disorganized, incomplete, and few even made no sense. This complexity in data grew as it was diverse and came uncleaned, and disjointed from different sources. To top this, enterprises started working with a lot of data and BI tools, and the people who worked on it were diverse and came from different backgrounds.
Bringing order, speed, and legitimacy to the entire organization starting from the data operations to business reporting is why DataOps came into existence.
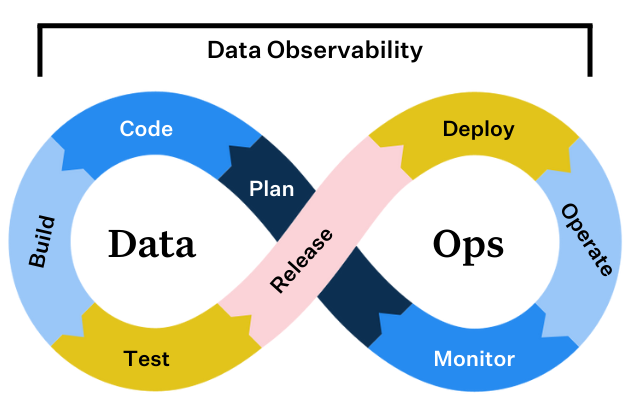
DataOps is a new independent approach to data analytics. Bringing together several tools and various levels of people in the organization into a common ground for better organization and development of data is called DataOps.
DataOps is mostly about the interconnected nature from design to development of data. This process involves a proper framework of operations between Data Analysts, Data Scientists, Developers, and Operationalists with data transformation, and delivering fast and insightful analytics.
The Ideologies behind DataOps
Agile methodology

- Agile refers to several methodologies that focus on the step-by-step, iterative process. These experimentations would expect teams to get tangible products and features out quickly at the end of every sprint. This strategy has been widely implemented in various domains and similarly, data analytics also seems to have benefited from it. It is not a prescriptive solution for enterprises rather it's a strategy for working with the data.
- With Agile methodology, the users are in line with the data and development teams. These iterations are kept short, and consistent validation from the users and stakeholders in the form of feedback for every iteration helps teams never drift away from the target.
- One of the key traits of Agile analytics is automating any process that is done more than once. This involves test automation, which enables users to revalidate that everything is running as expected, and build validation, which enables users to revalidate new versions of the software or feature in an automated fashion.
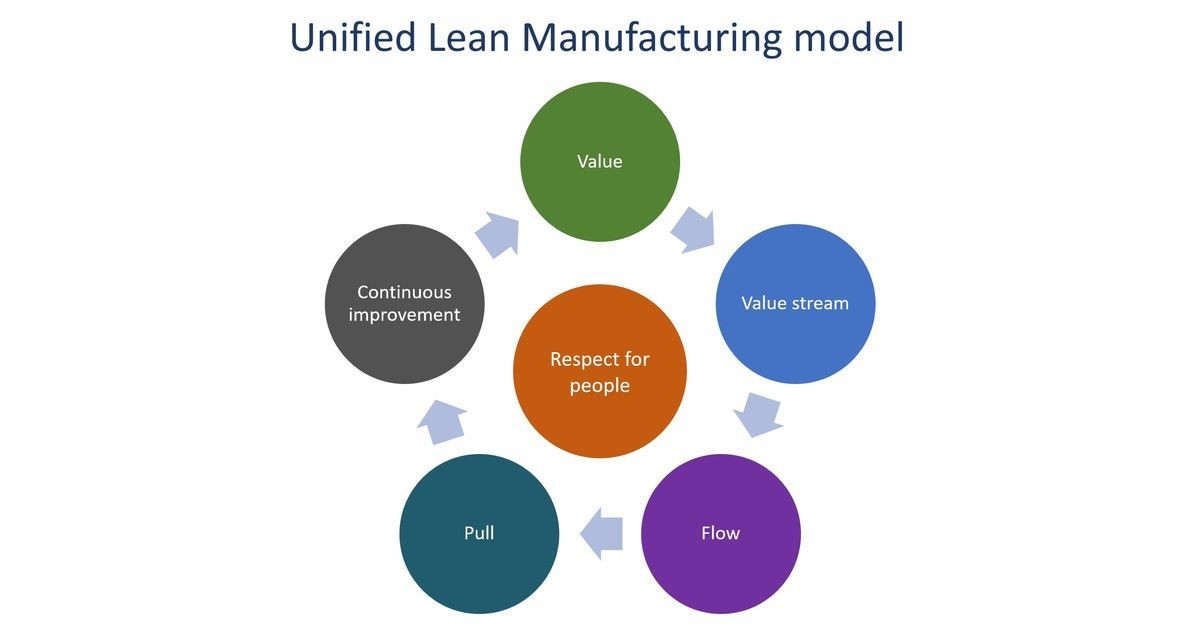
Lean Manufacturing

- Lean manufacturing is deriving raw data and transforming them into data of high efficiency. A statistical process control method where the quality of data is improved exponentially by filtering out the data that serves no purpose.
- The more useless data is eliminated, the more legitimate data is identified. This helps the data team avoid unnecessary efforts on data cleansing, transformations, modeling, analysis, and also the analytics part. This saves time and extensively increases the reliability of the data and the insights it produces.
- These data quality checks can be automated, and the data citizens in your organization can model a filter on what sort of data can enter the system, this automatically allows just the valid data that's been defined by the data team.
DevOps

- DevOps is a practice where development, operation, and business teams work in parallel to extract the best quality outcome in a shorter span of time. A methodology that helps enterprises meet rapidly changing market demands.
- DataOps applies DevOps technologies to transform data insights into production deliverables. These technologies include real-time monitoring which helps in optimizing the data pipelines. This seamlessness in implementing the inputs provided by users and business teams is with the help of DevOps principles.
- DevOps principles include aligning people with their goals and bringing automation throughout the development process. DataOps incorporates these principles to improve the efficiency of the data cycle and brings a goal-oriented approach throughout the organization by defining roles for every data citizen.
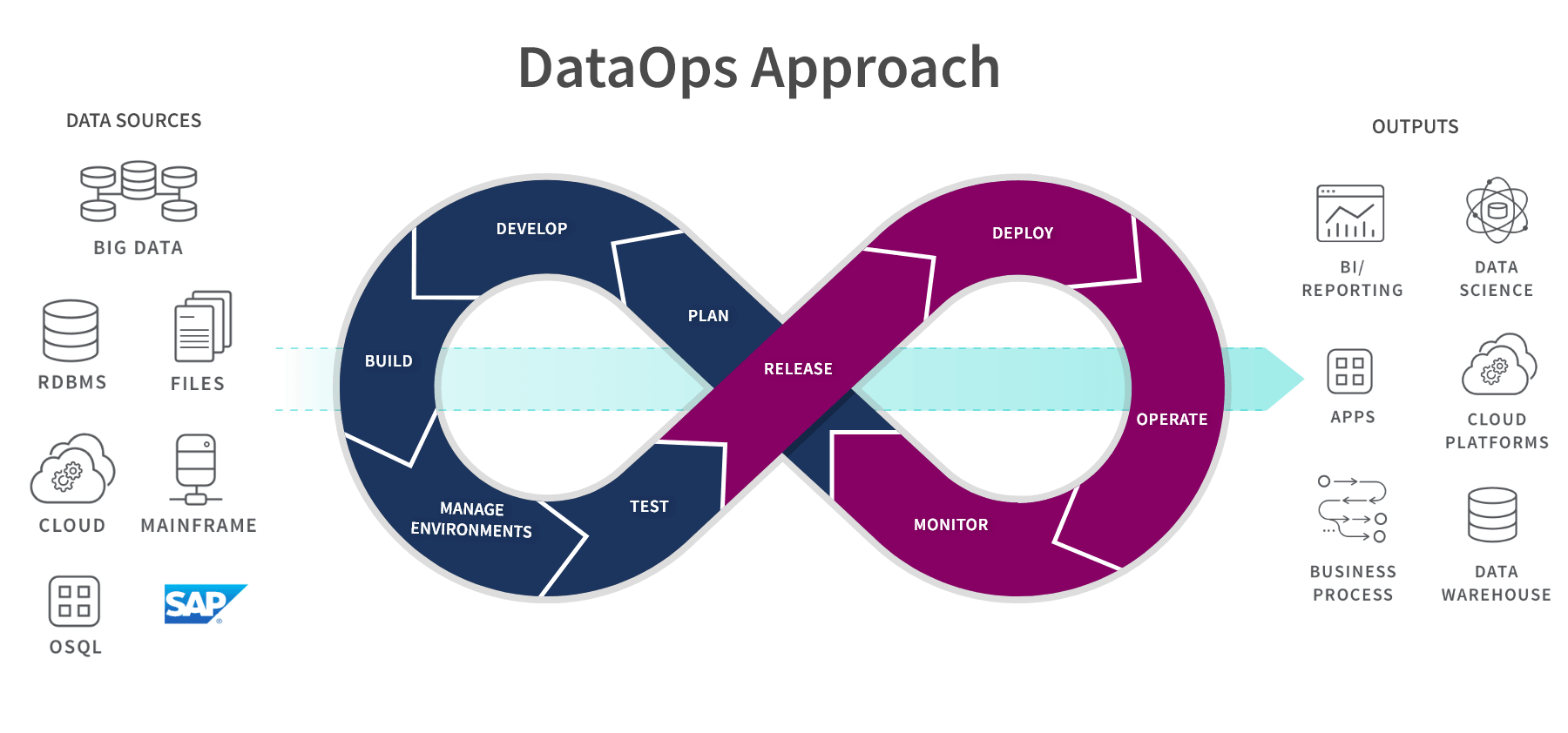
How DataOps works

DataOps combines DevOps and Agile processes to manage data to meet business goals. For instance, it can be used to improve the lead conversion rate by optimizing marketing and product recommendations. DevOps processes optimize code, product builds, and delivery, while Agile processes manage data governance and analytics.
DataOps consists of more than just writing code; improving and streamlining the data warehouse is just as essential. Like the Lean Manufacturing process, DataOps utilizes Statistical Process Control (SPC) to monitor and maintain the data analytics pipeline. This ensures the statistics remain within reasonable parameters, optimizes data processing, and enhances data quality. SPC also allows for immediately detecting anomalies and errors, alerting data analysts to act quickly.
Benefits of DataOps for Data Quality
The mission and purpose of DataOps is to create agile, scalable, and controllable data workflows, feed data consumers with the data they need, improve the speed of analytics deployment, and provide robust governance and cataloging capabilities.

Adopting a DataOps strategy can offer organizations many advantages, such as:
- Provides trustworthy real-time data insights.
- Reduces the cycle time of data science applications.
- Enhances team and individual interaction.
- Utilize data analysis to increase transparency and anticipate all potential outcomes.
- Establishes systems that can be repeated and reused code whenever feasible.
- Ensures better quality data.
- Creates a unified, interoperable data hub.
The roles and people behind DataOps:
To begin a data-driven culture within the organization, the leaders who drive transformation must define the roles played by each and every employee, and how their contributions would reflect on the goals set towards a successful DataOps practice.
The contribution of data might be from various levels of teams across the organization in the form of data. However, Data Architects, Data Engineer, Data Analyst, and Business Users are the ones who play a vital part in DataOps practices, right from collating the raw data to transforming them into actionable insights.

Implementing DataOps helps enterprises overcome these challenges
Inefficiencies in the data
Error-free data gives error-free analytics. Before carrying on with the analytics, the collated data needs to be checked and made to determine if it's legit or not. This is possible only by cleansing, organizing, transforming, and modeling the data to see if they produce insight of any use.
To tackle the collection of unnecessary data, the garnered data can be put under a series of data quality checks which filters out data that serve no use to the pipeline flows and models the organization works with. DataOps's Lean principles help to decrease the volume of data collated and also improve the quality of it.
Deployment difficulties due to limited collaboration
Too often, the development teams solely face the burden of fixing bugs and deploying changes as it is a time-critical process. In such scenarios, limited collaborations result in siloed communication and sending requests back and forth between teams which cause operational delays.
DataOps practice enables the Data team, Development team, Engineering team, and IT operations team to work together. Managing tickets based on priority and frequent deployment with real-time feedback within the teams and also with the users leads to successful DataOps practice.
Asynchronous goal-setting
When implementing DataOps's Agile practice, working with new product updates and user tickets is performed in the form of sprints. These sprints are scrutinized every now and then where constant feedback is given from both the management heads and also from the users.
Post the sprints, as the organization understands the issues, as easy as it would be to make a few tweaks or push the same practice to a greater extent. This real-time feedback loop helps organizations study and rectify errors as soon as possible. This not only hands the users a working feature or fixes some bugs after every sprint, but it also allows teams to re-evaluate these changes and set goals in real-time.
Frequently Asked Questions FAQs - What is Dataops?
What is DataOps in simple terms?
DataOps is an agile methodology that aims to improve the collaboration, integration, and automation of data pipelines and data-driven processes.
What is the difference between DevOps and DataOps?
DevOps focuses on the software development and deployment lifecycle, while DataOps is specifically tailored to the unique challenges of data-driven processes. DevOps emphasizes continuous integration and delivery, whereas DataOps also includes data quality, data governance, and data security as key priorities.
What are the objectives of DataOps?
The primary objectives of DataOps are to
- improve data quality,
- reduce data pipeline failures,
- increase data pipeline agility, and
- enhance collaboration between data teams and stakeholders.
What is the meaning of OPS data?
OPS data refers to the operational data generated by various systems and applications within an organization. This data is often used to monitor and manage the day-to-day operations of a business, and it can be leveraged for various analytical and decision-making purposes through the application of DataOps principles.
What are the stages of DataOps?
The typical stages of the DataOps lifecycle include
- data acquisition,
- data preparation,
- data processing,
- data analysis, and
- data delivery
What is DataOps in AWS?
DataOps in AWS refers to the set of practices and tools used to automate and streamline the data management and analytics processes within the AWS cloud environment. DataOps in AWS aims to improve the reliability, scalability, and agility of data-driven applications by leveraging AWS services such as AWS Glue, Amazon Athena, and Amazon Redshift.
Is MLOps part of DataOps?
Yes, MLOps (Machine Learning Operations) is considered a subset of DataOps. While DataOps focuses on the broader data management and analytics lifecycle, MLOps specifically addresses the challenges in deploying, monitoring, and maintaining machine learning models in production.
What is DataOps in AI?
DataOps in the context of AI refers to the practices and tools used to manage the data lifecycle for artificial intelligence and machine learning projects. This includes the efficient collection, preparation, and curation of data, as well as the integration of data pipelines with model training and deployment processes.
What is the difference between DataOps and data engineering?
Data engineering is primarily concerned with designing, developing, and maintaining data infrastructure, including data pipelines, data warehouses, and data lakes. DataOps, on the other hand, emphasizes the automation and optimization of the entire data management lifecycle, from data collection to data-driven decision-making.








{kind=link}
{kind=link}
{kind=link}
{kind=link}