


In the world of data management, organizations constantly seek efficient ways to store, process, and utilize their vast amounts of data. Two prominent approaches that have gained attention in recent years are Data Mesh and Data Lake.
In this article, we will delve into the details of both concepts, highlighting their key differences, advantages, and considerations. By the end, you will better understand which approach is better suited for your organization's data management needs.
What is a Data Mesh?

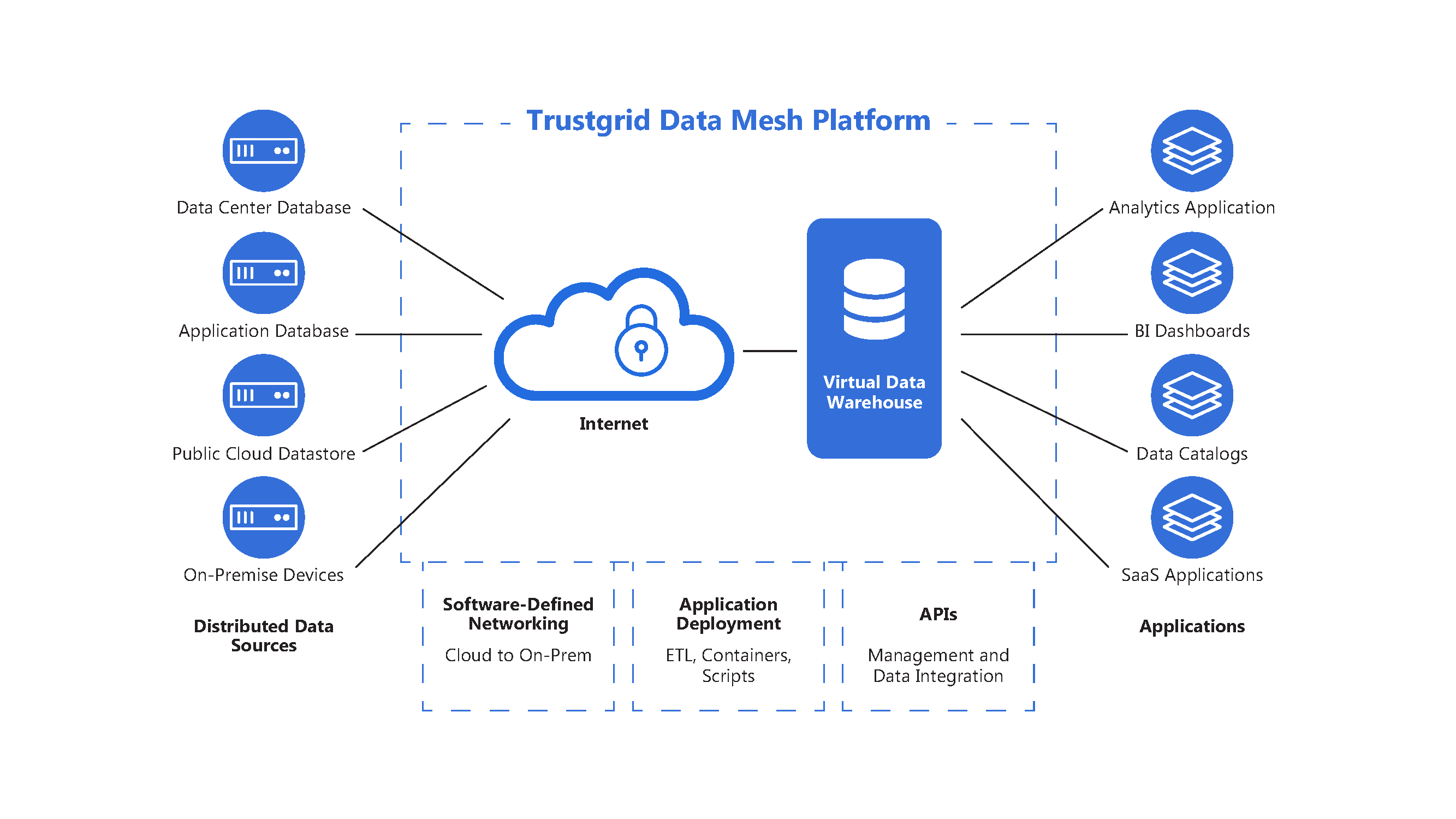
Data Mesh is a decentralized approach to data management that emphasizes domain-oriented teams and distributed data ownership. It shifts the traditional centralized data architecture to a more federated model, empowering individual teams or business units to take ownership of their data products.
With Data Mesh, each team manages its data infrastructure, governance, and processes, while collaborating with other teams to establish a network of interoperable data products. This approach aims to increase data management agility, scalability, and autonomy.
What is a Data Lake?

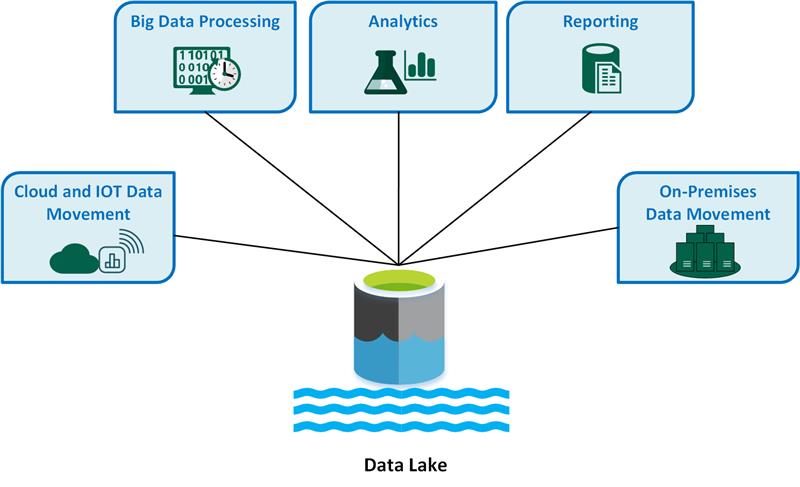
Data Lake is a centralized repository that stores large volumes of raw, unprocessed data from various sources. It provides a scalable and cost-effective solution for storing structured, semi-structured, and unstructured data. Data is stored in its native format without any predefined schema, allowing for flexibility in data exploration and analysis.
The Data Lake acts as a single source of truth, supporting diverse data processing and analytics capabilities. It enables data scientists, analysts, and other users to access and extract insights from the data.
Data mesh vs data lake: Data Structure and Governance
One significant difference between Data Mesh and Data Lake lies in their approach to data structure and governance.
Data Mesh

It encourages domain teams to take responsibility for their data products, including defining data models, schemas, and governance rules specific to their domains. This decentralization enables flexibility and agility, but it also requires strong collaboration and communication across teams to maintain consistency and data quality.
Data Lakes

Data Lakes do not enforce strict governance upfront. Instead, they provide a raw data storage layer, allowing users to explore and define schemas and governance structures as needed during data processing.
Data mesh vs data lake: Data Ownership and Accessibility:
Data Mesh
They promote the concept of data product ownership, where individual teams have autonomy over their data products. This ownership extends to data quality, reliability, and availability. Each team is responsible for ensuring their data products meet the required standards and are accessible to other teams through well-defined interfaces.
Data Lake
They offer centralized storage and accessibility. They provide a unified data repository where various teams can access and analyze data without the need for explicit ownership. Data access controls and permissions can be applied to ensure proper data governance.
Data mesh vs data lake: Scalability and Flexibility
Scalability and flexibility are key considerations in data management.
Data Mesh
It embraces scalability by decentralizing data ownership and infrastructure. Each team can scale its data products independently, adapting to specific requirements and changing workloads. This flexibility allows teams to experiment with different technologies and tools best suited for their domains.
Data Lake
Data lakes offer scalability by leveraging distributed storage and parallel processing technologies. They can handle massive data volumes and support various data processing frameworks. However, introducing changes to the underlying data structure or schema in a Data Lake may require careful planning and migration strategies.
Data mesh vs data lake: Data Processing and Analytics
Both data lakes and data mesh provide opportunities for data processing and analytics.
Data Mesh
It promotes the use of domain-specific data processing frameworks and tools, allowing teams to choose technologies that best suit their needs. This enables tailored analytics and processing capabilities for specific domains.
Data Lakes
Data lakes with their central repository, support a wide range of processing and data analytics tools. They can integrate with popular frameworks like Apache Spark and Apache Hadoop, enabling batch processing, real-time analytics, and machine learning applications.
Data mesh vs data lake: Data Governance and Data Quality
Effective data governance and data quality management are essential in any data management approach.
Data Mesh
It places responsibility on individual teams to establish data governance practices specific to their domains. This distributed ownership may require establishing cross-team collaboration frameworks and defining standard practices.
Data Lakes
Data lakes while providing a centralized data repository, require careful attention to data quality and governance. Implementing data governance practices, such as data profiling, data lineage tracking, and metadata management, ensures data consistency, reliability, and compliance.
Data mesh vs data lake: Adoption and Organizational Impact
Data Mesh
Adopting Data Mesh requires a cultural shift within the organization. It requires strong collaboration, effective communication, and a clear understanding of domain boundaries. Implementing Data Mesh also involves enabling teams with the necessary skills and resources to manage their data products.
Data Lakes
Data lake adoption requires establishing a centralized data infrastructure and investing in technologies that support data ingestion, storage, and analytics at scale. Organizations must also consider the impact on existing data pipelines, data integration processes, and data security measures.
Data mesh vs data lake: Data Integration and ETL
Data Mesh
In a Data Mesh architecture, each domain team is responsible for data integration and ETL processes within their domain. This means that teams have the autonomy to choose the tools, technologies, and processes that best fit their specific data requirements. In contrast, Data Lakes often involve a centralized approach to data integration and ETL.
Data Lakes
Data is ingested into the Data Lake, and then centralized processes and pipelines are established to transform and load the data into usable formats for analysis and consumption by various teams.
Data mesh vs data lake: Data Discoverability and Metadata Management
Data Mesh
It promotes the concept of "Discoverable Data Products" where domain teams make their data products discoverable and accessible to other teams through well-defined interfaces and metadata. Each team maintains metadata about their data products, including data schemas, data definitions, and data usage guidelines.
Data Lakes
Data Lakes typically have metadata management systems in place to track information about the data stored in the lake. Metadata includes details about data sources, data formats, data transformations, and other relevant information to aid in data discovery and understanding.
Data mesh vs data lake: Data Privacy and Security
Data Mesh
It emphasizes domain ownership, which means that each domain team is responsible for ensuring data privacy and security within their respective domains. Teams establish their own data access controls, data encryption mechanisms, and compliance measures based on specific privacy and security requirements.
Data Lakes
In Data Lakes, privacy and security measures are often implemented at the centralized level. Data access controls, encryption, and compliance policies are established at the Data Lake level to ensure data privacy and security across all the stored data.
Data mesh vs data lake: Cost Considerations
Cost considerations differ between Data Mesh and Data Lakes.
Data Mesh
It allows teams to independently choose the technologies and infrastructure that best fit their needs and budget. This decentralized approach can lead to varying costs across different teams.
Data Lakes
It provides a centralized infrastructure that can potentially lead to cost savings in terms of storage and processing. By leveraging scalable cloud-based solutions, organizations can benefit from economies of scale and pay-as-you-go pricing models.
Data mesh vs data lake: Organizational Culture and Mindset
Data Mesh
It requires a cultural shift within the organization, promoting a data-driven mindset and fostering collaboration across teams. It emphasizes the importance of data as a product and encourages teams to take ownership of their data domains.
Data Lakes
It requires a data-driven culture and a more centralized mindset as they provide a shared repository for data storage and analytics. The organization's existing culture, readiness for change, and ability to adapt to a decentralized or centralized approach can influence the choice between Data Mesh and Data Lakes.
Data mesh vs data lake: Maturity and Industry Adoption
Data Mesh
It is a relatively newer concept and is still evolving. It is gaining traction within certain industries and organizations that value agility, autonomy, and scalability.
Data Lakes
They have been widely adopted across various industries for many years. They have a more mature ecosystem with established best practices, tools, and technologies. The level of maturity and industry adoption can impact the available resources, community support, and expertise for each approach.
Conclusion:
Data Mesh and Data Lake represent two distinct approaches to data management. Data Mesh emphasizes decentralized ownership, domain-oriented teams, and collaboration, allowing for flexibility and agility.
Data Lakes provides a centralized repository for raw data, supporting scalability, and enabling a wide range of data processing and analytics capabilities.
When deciding between the two, organizations should consider factors such as their data governance approach, data accessibility requirements, scalability needs, data processing capabilities, and the organizational readiness for change.
Frequently Asked Questions FAQs - Data Mesh Vs Data Lake
What is the difference between a data lake and a data mesh?
A data lake is a centralized repository that allows storing all types of data in its raw form without any structure. Wheraes, data mesh focuses on breaking down monolithic data systems into smaller, more manageable units that different teams can independently manage.
How is data mesh different?
Data mesh is different from traditional data management approaches as it emphasizes decentralization, domain-oriented ownership, and self-serve capabilities for data consumers.
What is the difference between Delta Lake and data mesh?
Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark and big data workloads. In contrast, data mesh is a conceptual framework for organizing how companies manage distributed datasets across their organization.
Does data mesh replace data lake?
Data mesh does not replace data lake but rather complements it by introducing a new way of organizing and accessing distributed datasets within an organization. Data mesh leverages existing data lakes by breaking them down into smaller, more manageable units called domains, which individual teams can independently manage.
Does data mesh use a data lake?
While data mesh may use some components of a traditional data lake architecture, such as storage layers like Delta Lake or Hadoop Distributed File System (HDFS), its main focus is on decentralization and domain-oriented ownership of datasets.
What is the difference between a data mesh and a data mart?
A data mart is a subset of a larger enterprise-wide data warehouse that is focused on providing access to specific sets of information for particular user groups or departments within an organization. In contrast, data mesh is a newer architectural paradigm that focuses on decentralizing control over distributed datasets across an organization while enabling domain-specific ownership and governance.
What is a data mesh model?
The data mesh model proposes a shift in how organizations manage and share their datasets by decentralizing control over the creation, maintenance, and consumption of data assets. This model advocates for breaking down monolithic central repositories into smaller domain-specific datasets that are independently managed by cross-functional teams.
What are the 4 pillars of data mesh?
The four pillars of the data mesh model are
- domain-oriented decentralized ownership,
- product thinking for internal services,
- self-serve platform design principles, and
- federated computational governance
What is the role of data mesh?
Data mesh enables organizations to manage their distributed datasets better by promoting decentralization, domain-oriented ownership, self-service capabilities for users, and federated computational governance. Data mesh acts as a centralized data platform.
What problems does data mesh solve?
Data mesh solves several problems associated with traditional centralized approaches such as scalability, performance bottlenecks caused by centralized architectures, lack of agility in responding to changing business requirements quickly, and difficulties in ensuring proper governance over distributed datasets.
Is data mesh only for analytics?
Data mesh is not only limited to analytics but can also be applied across data domain such as machine learning models development/deployment workflows or real-time event processing pipelines.








{kind=link}
{kind=link}
{kind=link}
{kind=link}