


Data is the backbone of any organization seeking to derive valuable insights from it. However, raw data is often messy, incomplete, or incorrect, which can highly affect its usefulness for data analysis. This is where data cleaning comes to the rescue. Data cleansing is a crucial process that ensures proper data quality making it ready for analysis.
In this article, we will dive into the world of data cleaning, exploring its significance, techniques used, challenges faced, and best practices.
What is Data Cleansing/Cleaning?

Data cleaning also known as data cleansing refers to the process of detecting and fixing errors in datasets to improve their quality and reliability for analysis purposes. It involves removing duplicate data, identifying and computing missing values, regularizing formats, detecting and eradicating outliers, and assuring adherence to predefined rules.
Benefits of Data Cleaning
Accuracy in Reports:
Cleaned data ensures better accuracy in analytical reports and dashboards. By eliminating inaccuracies and inconsistencies within datasets, decision-makers can rely on sound information to drive effective strategies.
Improved Efficiency in Business Process:
Quality data reduces the time spent on troubleshooting issues during analysis since analysts can focus on extracting insights instead of dealing with faulty information.
Cost Savings:
Inaccurate data can lead to costly mistakes in business operations and marketing campaigns. By investing in thorough data cleaning processes, organizations prevent unnecessary expenses arising from poor-quality information.
Types of Data Cleaning Strategies

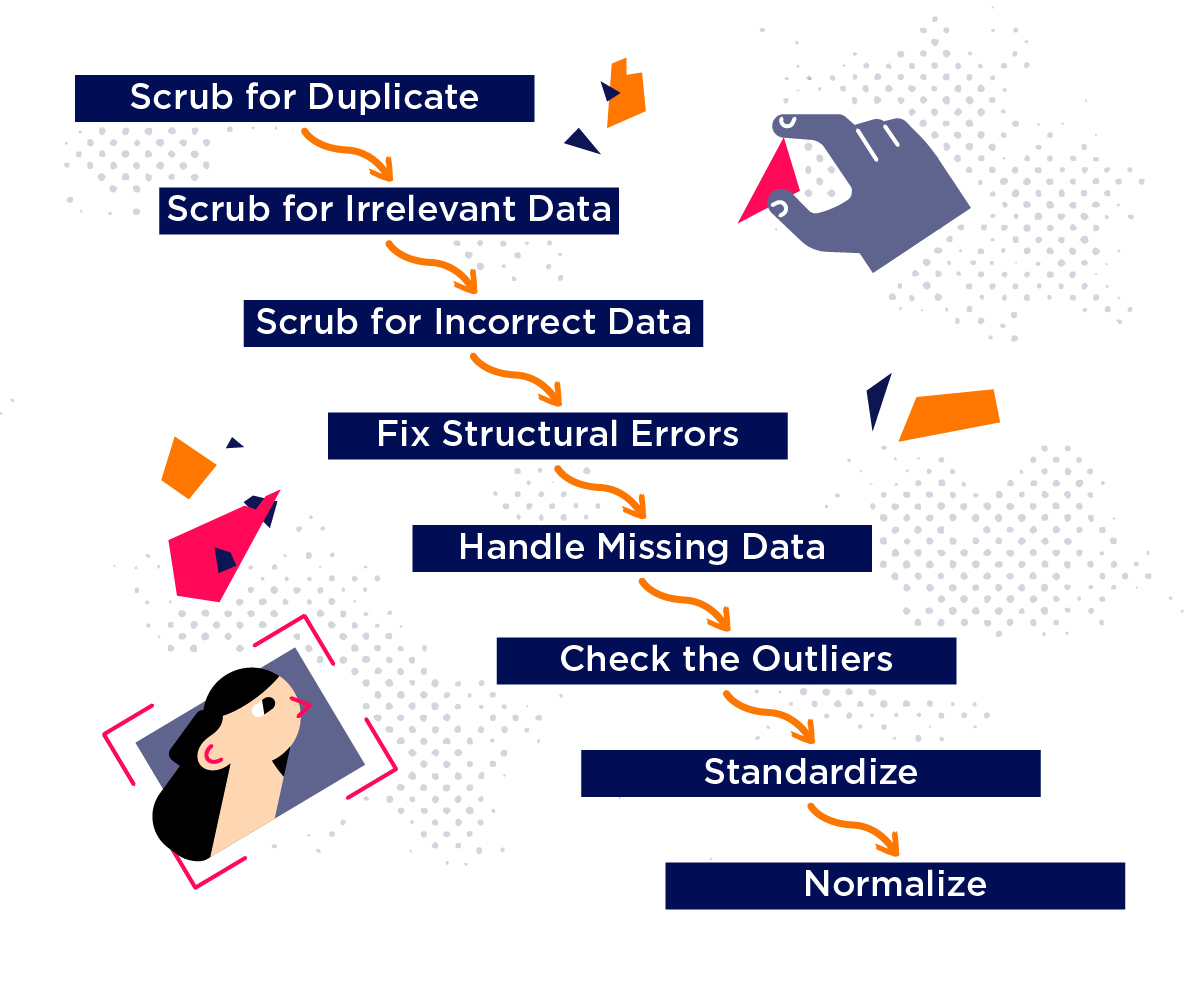
The data cleaning process is a crucial step in the data analytics process. In this section, we will discuss various types of data-cleaning techniques commonly used by data scientists or data analysts to rectify data errors, structural errors, and syntax errors.
Handling Missing Data Values:
One of the most common issues encountered during the data analysis process is incomplete data values. Missing values can arise due to various reasons such as human error by manual data entry during data collection, or simply because of the unavailability of certain information. There are several strategies to handle missing values some of them include:
- Deleting rows or columns with missing values
- Estimating missing values based on other related variables

De-Duplicating Data:
When multiple entries of the same observation exist within a data set then data duplication occurs. This could be due to inaccurate data entry or merging multiple datasets without proper consideration. Duplicate records can misinterpret statistical analysis results thus leading to false inferences. To handle such a situation data cleaning involves identifying duplicate values and either removing them or merging them into a single record based on some criteria.
Correcting Inconsistent Data:
Inconsistencies in data refer to clashing information within datasets. For example, a customer data set might contain different representations of the same category (e.g. 'Female', 'F', 'Woman'). Standardization of such variations of data is necessary to perform further analysis. This can be achieved by incorporating Techniques such as string manipulation, and regular expressions in our data cleaning process.
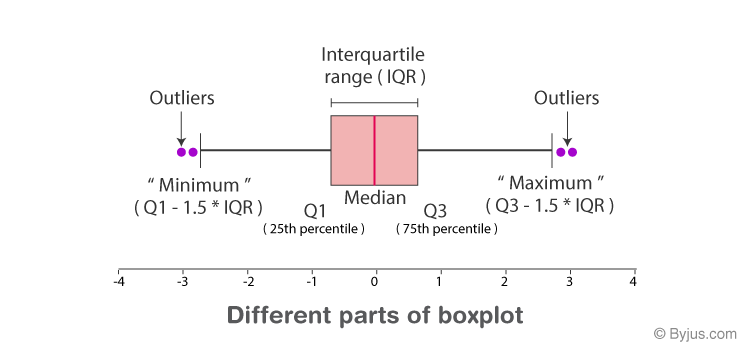
Handling Outliers Using Boxplots:
Outliers are extreme observations that deviate significantly from the overall pattern of the data set. Identifying outliers is important for keeping accuracy in statistical analysis as they can highly influence the outcomes of model performance. Different methods like statistical tests, and visualization techniques like boxplots can be created, to identify and handle outliers.

Normalizing Different Data Formats:
Data collected from various sources may have differing formats or units. For effective data analysis, it is necessary to normalize the data by converting it into a consistent format. This could involve converting different date formats into a standardized format or normalizing variables to a common scale.
Dealing with Typos and Spelling Errors:
Typos and spelling errors are common in textual data fields which can lead to difficulties in analysis if not addressed properly. Data cleaning techniques for handling typos include techniques like spell-checking using dictionaries or libraries specifically designed for this purpose.
Challenges Faced in the Data Cleaning Process
Data cleaning is not without its challenges, some of the most common challenges faced during the data cleaning process are listed below:
Handling large volumes of data from various sources raises the complexity of the data-cleaning process, requiring efficient tools and techniques.
Decisions during the data cleaning process often involve some judgments based on assumptions or gut feeling, which poses a lack of authenticity and incorrect analysis, if not managed properly.
Cleaning massive datasets within a stipulated amount of time can be overwhelming, requiring prioritization and automation of tasks wherever possible.
When merging multiple datasets, problems like inconsistent formats, duplicate values, etc can pose data integration challenges that need to be resolved before proceeding with the cleaning process.
Best Practices for Effective Data Cleaning
To ensure a successful data cleaning process the best practices listed below should be followed:
Understanding the objective or data context:
Gain in-depth knowledge of the dataset's goal, desired outcomes, and possible limitations to guide the cleaning process effectively.
Document and develop a data cleaning procedure:
Define clear objectives that you want to attain, set data quality criteria, establish some rules for handling missing values/outliers/duplicates, and document every step taken during cleaning.
Utilize automation and data integration tools:
Utilize tools and software or even programming languages like Python to automate redundant tasks in the data cleaning processes whenever feasible.
Maintain documentation of the steps taken during the data cleaning process:
Maintain detailed documentation throughout the entire process to facilitate reproducibility of any encountered issue and maintain transparency in data cleaning operations.
Continuously validate results to ensure accuracy:
Always validate cleansed data sets against predefined metrics or statistical methods continuously to guarantee the intended data quality standards are met.
Data cleaning plays a key role in transforming raw data into reliable and high-quality information for analysis. By understanding its importance, and employing appropriate data cleansing tools, organizations can uncover the full potential of their data sets.
Getting Started with Sprinkle Data
Sprinkle Data is a self-service BI tool that makes the data analysis process easy. With its intuitive interface, Sprinkle Data makes the process of cleaning and refining datasets effortless by using Python notebooks or simply using its powerful SQL transformation feature.
Frequently Asked Questions FAQs - What is Data Cleaning?
What do you mean by data cleaning?
Data cleaning refers to the process of identifying and correcting or eradicating errors, inconsistencies, and inaccuracies in datasets.
What are examples of data cleaning?
Examples of data cleaning include removing duplicate records from a dataset, imputing missing values by using statistical methods, correcting formatting issues like inconsistent date formats, and resolving inconsistencies between different data sources.
How do you cleanse data?
To cleanse data, one can use techniques like removing duplicates using algorithms or unique identifiers, filling in missing values using statistical methods or imputation techniques, standardizing data formats through string manipulation functions, and resolving inconsistencies.
What is data cleaning in ETL?
In ETL (Extract, Transform, Load), data cleaning is an important step in the transformation phase. During this phase, the extracted raw data undergoes various operations like filtering unwanted records, merging multiple datasets, transforming variables into desired formats, and cleansing the data to ensure its quality before loading it into a target system.
Is data cleaning part of the ETL process?
Yes, data cleaning is an integral part of the ETL process as it ensures that the transformed data is accurate, consistent, and reliable for further analysis or storage purposes. Without proper data cleaning steps in place during ETL, the resulting insights can be inconsistent and may be unreliable.
Which tool is used to clean data?
Some popular data cleaning tools include Sprinkle Data, OpenRefine (formerly Google Refine), Trifacta Wrangler, Talend Data Preparation, and Microsoft Excel's built-in features like filters and formulas for cleaning small datasets.
How do I clean data in SQL?
To clean data in SQL databases, one can use various SQL statements like
- SELECT DISTINCT to remove duplicate records
- UPDATE to modify inconsistent or incorrect values
- DELETE to remove unwanted records
- CASE WHEN statements to handle missing values
- JOINs to merge data from multiple tables, etc.
Why data cleaning process is important?
Data cleaning is important because it improves the quality and reliability of data, leading to more accurate analysis and decision-making. Clean data reduces errors, inconsistencies, and biases in datasets, providing a solid foundation for further processing or analysis tasks.
Is data cleaning data processing?
While data cleaning is an essential part of the overall data processing pipeline, it focuses specifically on identifying and correcting errors, inconsistencies, and inaccuracies in datasets. On the other hand, data processing contains a broader range of activities including extraction, validation, transformation, aggregation, analysis, visualization, and storage of large volumes of data.
What is the difference between data cleaning data transformation and data scrubbing?
Data cleaning aims to improve the quality and accuracy of raw datasets by detecting and correcting errors or inconsistencies. Whereas data transformation focuses on manipulating clean datasets to make them suitable for specific analytical purposes such as building predictive models or generating reports. Data scrubbing is a subset of the data cleaning process that specifically involves removing redundant values or old data from the data set.








{kind=link}
{kind=link}
{kind=link}